株式会社リブセンスのTechNightに参加してきました
リブセンスのエンジニアの方にJuliaの話をしてほしいとの話を受けまして、LTですがJuliaのお話をしてきました。 このようなエンジニア中心の勉強会を毎月行っているようです。
LT大会「TechNight」、7/27(月) 19:30〜開催します。 | LIVESENSE made*

せっかくですので、このブログ記事で内容を簡単にまとめておこうと思います。 タイトルは「Juliaは何処から来たのか、Juliaとは何か、Juliaは何処へ行くのか」ということで、Juliaの発端と機能、それに今後どうなっていくのかを簡単にお話しました。
事前にJuliaを知っているかということを尋ねたのですが、20人ほどいるなかで、ひとりだけ去年ちょっと触ってみたという方がいらっしゃいました。 それ以外の方は、Juliaのことを初めて知ったようです。
Juliaは何処から来たのか
Juliaの開発はボストンのMITで始まり、現在でも開発の中心になっています。

Founders
言語を始めにつくった人達は次の4人です。
Jeffはプログラミング言語のスペシャリストで、femtolispという非常に小さいSchemeのような言語の実装を作っています。これは、Julia本体のフロントエンド部分にも使われています。 Edelman先生はMITの教授であり、JeffのPh.D.の指導教員でもあるようです。 より詳しい経緯はWIREDの記事にもなっていますので、読んでみてください。
Repository
開発はすべてGitHubでオープンに行われていて、だれでも参加することができます。
Why They Created Julia
そもそも何故新しいプログラミング言語が必要なのでしょうか。 その理由は、Juliaの最初のブログ記事で説明されています。
In short, because we are greedy.
一言で言えば、貪欲だからだ。
これは、先ほどのブログの冒頭からの引用です。 どういう意味かは記事を読んでいただけると分かるのですが、まとめると、
- Rubyのように動的性質を持っていて、
- Cのように高速で、
- Lispのようにマクロもあって、
- Rのように統計が得意で、
- Perlのように文字列処理もできて、
- MATLABのように線形代数もできる
- シンプルでオープンでインタラクティブな言語がほしい
ということになります。そして、それを実現したのがJuliaです。
Juliaとは何か
Juliaの見た目を知るためにクイックソートのコード例を示します。
quicksort(xs::Vector) = quicksort!(copy(xs))
function quicksort!(xs::Vector, lo=1, hi=endof(xs))
if lo < hi
p = partition(xs, lo, hi)
quicksort!(xs, lo, p - 1)
quicksort!(xs, p + 1, hi)
end
return xs
end
function partition(xs, lo, hi)
pivot = div(lo + hi, 2)
pvalue = xs[pivot]
xs[pivot], xs[hi] = xs[hi], xs[pivot]
j = lo
@inbounds for i in lo:hi-1
if xs[i] <= pvalue
xs[i], xs[j] = xs[j], xs[i]
j += 1
end
end
xs[j], xs[hi] = xs[hi], xs[j]
return j
end
多くのスクリプト言語と共通するのは、
- 簡潔な文法 (MATLAB風)
- 変数の型宣言が不要
- 引数の型指定が不要
というところでしょう。 一方、あまり見られない特徴としては、
が挙げられます。 型推論とJITコンパイルで、変数の型が決定できるときには非常に高速なコードが生成されます。 マクロはLispに強い影響を受けていて、Cプリプロセッサのような文字列置き換えでなく、式を書き換えることができるものです。 コンパクトなデータ構造というのは、型定義の際にそのデータ構造が占める容量が決定でき、各メンバーへのポインターなど余計なサイズを取らないということです。
Juliaの書きやすさと表現力は、標準ライブラリに現れています。
Juliaの標準ライブラリはほぼすべてJuliaで書かれており、Cのライブラリの呼び出しもJuliaから簡単にできます。

そして、先ほどのクイックソートは、型指定などは無いにも関わらず、とても高速に動きます。 同じように書いたC言語並みの速度です。 さらに、動的にコードを生成しますので、例えば浮動小数点数でなく整数に対しても、コードを変更したりせず高速に動きます。

数値型
元々科学技術計算を目的として作られていますので、数値型が豊富です。
符号付き整数型は8bit, 16bit, 32bit, 64bit, 128bitがそれぞれ用意されており、
Int8からInt128までわかり易い名前がついています。
同様に、符号なしの整数はUint64などと定義されています。
浮動小数点数も16bit, 32bit, 64bitがあり、Float64などと表記されます。
他には複素数や有理数、任意精度の数値の型もあらかじめ用意されています。
線形代数
ベクトルや行列の積や線形方程式の解、LU分解やSVDなども標準ライブラリにあり、 実装はOpenBLASやLAPACKなどの高速な実装を呼び出しますので、パフォーマンスも十分です。
多重ディスパッチ
Juliaの根幹をなす重要な機能が多重ディスパッチです。 これは、引数の型の組み合わせにより実行されるメソッドが切り替わるものです。
例えば、標準ライブラリにあるsum関数を考えると、
sum([1,2,3])とsum(trues(4))で異なる実装のメソッドが呼び出されます。
[1,2,3]の型はVector{Int}であり、trues(4)の型はBitVectorで、両者で(高速な)和の計算方法は異なります。
そのため、多重ディスパッチを利用して、別々に実装しているわけです。
この時に注目して欲しいのは、引数の型が型推論により決定できる場合は、呼び出しのオーバーヘッドがない点です。
このような特徴から、標準ライブラリでも多重ディスパッチは多用されています。
マクロ
@showや@assertなど、デバッグなどに便利はマクロが多数存在しています。
マクロはJuliaの式を実行前に書き換えることができるメタプログラミング機能です。
例えば、@show xとするだけで、変数xの値が、x => 42のように変数名付きで表示されます。
これは、普通の関数には不可能な仕組みです。
コード生成
自分の書いた関数や、ライブラリのコードが実際にどのように実行されるかは、@code_llvmと@code_nativeマクロを使えば確認できます。
それぞれ、コンパイルしたLLVM IRとネイティブのコードを表示してくれるため、最適化などの際に非常に重要です。
Juliaは何処へ行くのか
Juliaのバージョンは、以下の様なものがあります。2015年7月末の時点では、v0.3が最新版です。
- v0.1 ← 未開の地
- v0.2 ← もはや郷愁の念
- v0.3 ← いまここ
- v0.4 ← もうすぐ
- v0.5 ← 来年・再来年あたり
- v1.0 ← 未定
v0.4の新機能は、こちらで確認できます。
julia/NEWS.md at master · JuliaLang/julia · GitHub
Ecosystem
現在600以上のパッケージがあり現在も増え続けています。

Conference
先月にはJuliaCon 2015もありました。実ははるばるボストンまで行ってきたのでした。
様々な分野の方々がJuliaを実際に使っていて、とてもよい印象を持っているようです。
強力なスポンサーもついており、ムーア財団やBlack Rock, Intelなどが出資しています。 JuliaConにもGoogle, Facebook, Intelといった会社の方々がたくさん来ていました。
Julia Computing
Juliaの創始者達が、スタートアップを始めたようです。 Juliaのコンサル業などをしており、Julia自体は今後もオープンであり続けるようです。
JuliaTokyo
我々はJuliaTokyoというユーザグループを立ち上げ、年に数回勉強会も開いています。 次回はまだ未定ですが、是非都合が合えば参加してみてください。
質疑
いくつか現地で質疑や雑談で話したことを簡単にまとめておきます。
- Q1. 去年Juliaを使ったとき(v0.2)、起動がとても遅かったが、いまはどうなのか。
A1. 最新リリース版のv0.3では、標準ライブラリにプリコンパイル機能が入ったので、起動時間は大幅に短縮された。さらに次期バージョン(v0.4)では、外部パッケージのプリコンパイル機能が入るので、パッケージの読み込みも高速化する。
Q2. Webなどのツールはどうなのか。
A2. JuliaWebグループがサーバなどの環境を整備している。Juliaは各種専門グループがいくつかあり、オープンにツールを開発している。
Q3. Juliaはどういう使われ方を想定しているのか。
A3. Juliaは汎用プログラミング言語になることを目指している。インターフェースからコアの計算までを一つの言語で書けることを目指しつつ、数値計算のみならずPythonのように汎用的に使われるようにしようとしている。また、Juliaを組み込んで使う方法もドキュメントに記載されており、そのように別のツールの内部で使われる方向もあると思う。
Q4. 何かJuliaには問題はないのか。
A4. パフォーマンス上の落とし穴がいくつかある。基本的には型推論がうまく動かないコードや、オブジェクト生成に関する誤解が原因。マニュアルにPerformance Tipsのセクションがあるので、読むと良い。
Q5. JuliaのIDEみたいなのがあった気がするが、どうしたのか。
A5. Julia Studioは死んだ。現在はLight Tableとうまく連携するJunoというツールがあるので、これを使うと良さそう。個人的にはvimを使っている。
Q6. プレゼンに使っているそのツールはなにか。
- A6. IPython Notebookというもの。ローカルでJuliaの処理系が動いており、ブラウザからコードを実行し結果を確認できる。最近JupyterというツールとしてPythonに依存しない機能が分離し、JuliaやPythonのみならず、RやRubyなど様々な言語も実行できる。
所感
割りと多くの方がJuliaに興味を持ってくれたようでした。 ウェブの企業だと、プログラミング言語自体の実行性能を気にすることはあまり無いようですが、分析系の人達は今のRなどに不満があって、速くなるのならJuliaを使ってみるのもいいかもしれないと言っていました。 Juliaのマニュアルの日本語化は需要があるようで、完成すれば普及に一役買うかもしれません。
「シリーズ Useful R データ分析プロセス」をいただきました
著者の福島さんより、「データ分析プロセス」(共立出版)の御恵投いただきました。ありがとうございます。 この本はシリーズ Useful Rのうちの一冊のようです。よく見ると私のラボのOBである門田先生もトランスクリプトーム解析の本をこのシリーズで書かれているのですね。
本書の第1章から第5章にかけて、書名の通りデータ分析プロセス全体に関わる事項が網羅されています。 第1章では、データ分析とは何であって実データを扱う上でどのような問題に直面しうるのかを問題提起し、 いくつかの分析フレームワークを紹介しています。
第2章では、R言語を使ってデータフレームの扱いの基本を確認しています。新刊だけあって、伝統的なRの標準パッケージのみならず、比較的最近になってRの世界では一般的になった新しいパッケージの導入もしています。 特にdata.tableとその周辺ツールに関しては、大規模データを扱う際には必須のツールになってきている感じがします。
第3章に入ると、分析前の前処理の話に移り、実データには必ず存在する欠損値と外れ値への対応方法が多くのページを割いて解説されています。 多くの文献を引いて起こりうるパターンと解決方法をコンパクトかつ網羅的に紹介しているので、ここだけでも読む価値があると思います。
続く第4章と第5章が本書のメインになるのでしょう。データから予測モデルを構築する具体的手法と実例を約100ページにわたって解説しています。 ハンズオン・セミナーのように実際にRのセッションへ打ち込みながら結果と説明を読んで、まとまりのある実データでのパターン抽出プロセスと評価方法を学んでいくことができます。 私は特に4.2節の「頻出パターンの抽出」から学ぶところは大きかったです。
全体を通して参考文献も多く引用されているため、この本を足がかりとしてデータ分析の知識を深めていくような読み方もあると思います。 普段やっているデータ分析プロセスを明確にする目的でも、本書を読んでみると良いのではないでしょうか。
Julia Summer of Code 2015に採択されました
Julia Summer of Codeという誰も知らないプログラムに採択されました。 この手のプログラムに採用されたのは初めてなので、嬉しくてあちこちで言いふらしています(ウザくてごめんなさい)。 概要としては、最近話題(?)のJuliaというプログラミング言語で夏の間にオープンソースのプログラムを書いて、$5500とJuliaConへの渡航費サポートを受けようというものです。 実はJuliaの組織が去年のGoogle Summer of Codeの結果に味をしめて今年も応募したものの何故か落とされ、Gordon and Betty Moore Foundationに出資を受けたNumFocusに応募したところめでたく通って、7つにプロジェクトに出資できるようになったようです。 なのでGoogle Summer of Codeの代わりなのですが、アナウンスメントが5月23日で締め切りが6月1日という超短期の応募期間で、常にJuliaのニュースをチェックしてる人にしか知られていないと思います。
詳細はこちら: Julia Summer of Code 2015
それで私は何をやるかというと、BioJuliaというJuliaでバイオインフォマティクスのライブラリを作ろうというプロジェクトがあるのですが、このプロジェクトの下で配列解析のためのデータ構造とアルゴリズムを作ろうというものです。 具体的にはFM-indexを使ったショートリードの配列の検索などを実装する予定です。 このプロジェクトで私のメンターになってくださったのが、Gadfly.jlで有名なワシントン大のDaniel C. Jonesさんです。 彼はBioJuliaの創始者でもあり、Julia本体のコントリビュータ(コミッタ?)でもあります。
詳しくはこちらの提案書を読んでください: https://github.com/bicycle1885/JSoC2015/blob/master/Proposal.md
この企画の太っ腹なところが、ボストンのMITで開催されるJuliaConへの渡航費や宿泊費等のサポートが$2500も出るところです。 ということで、パスポート発行やESTA申請が滞り無く終われば、今月末にはJuliaを産んだMITへ行ってくることになります。
他の採択されたプロジェクトはjulia-usersから見ることができます。 マイナー言語でも続けてればいいことがあります。きっと来年もGoogle Summer of CodeかJulia Summer of Codeでは学生のコントリビュータを募集することになると思いますので、狙っている人は今のうちのJuliaのコードを書いて公開してみたりするといいと思います。
JuliaTokyo #3 を開催しました
昨日(4月25日)JuliaTokyo #3を開催しました。 イベントページはこちらです。
当日の発表資料などはこちらにあります。
今回私はLTで参加しました。 Juliaを始めた人がハマりやすそうな、パフォーマンスに関する落とし穴を3つ紹介しています。 言いたいことは、Juliaをチョット試してみて遅かったというケースは、何か勘違いをしていて 少しの工夫で数十倍速くなるということです。 スライドとコードサンプルも公開していますので、詳しくはそちらを参照くださいませ。
www.slideshare.net github.com
印象に残ったトークはAndreさんの"Deep learning sequence models (Deep RNN & LSTMs) in #julialang"で、 Recurrent Neural NetworkをJuliaで実装してパッケージとして公開しています。
Andreさんは実際に仕事でJuliaを使ってもいるようで、後で話した時には殆どJuliaで仕事をしているとも仰っていました。
また、最後に飛び入りLTで参加された@keithseahusさんのMessage Pack RPC実装のMsgPackRpcClient.jlがすごくイイなぁという感じです。 これはLT中にMETADATA.jlにプルリクを送り、実際にマージされて無事リリースされたようです👏 https://github.com/JuliaLang/METADATA.jl/pull/2507
こうしてJuliaにたくさんパッケージができてどんどん便利になっていくのは大変よいですね。
他には、JuliaTokyoのGitHubグループが公開され、ウェブページもできています。
こちらでは、ドキュメントの翻訳や疑問質問を解決する仕組みも用意していて、どんどん日本のJuliaコミュニティが 拡大していく息吹を感じます! これらの活動を盛り上げてくださってる@chezouさん、@soramiさん、ありがとうございます!
本家Juliaコミュニティと同様、JuliaTokyoもオープンでどなたでも参加できる勉強会・コミュニティを目指しておりますので、 Juliaが気になる方は是非とも次回ご参加下さい。
当日の様子はTwitterの togetter.com を御覧ください。
私は一応オーガナイザー側ですが、やりたい!と言っただけで、準備は全て@soramiさんや株式会社ブレインパッドの皆様によるものです。 この場で、改めてお礼申し上げます。本当にありがとうございました。
Juliaではfor文を使え。ベクトル化してはいけない。
タイトルはいささか誇張です。最後のセクションが一番言いたいことなので、そこまで読んでいただけたら嬉しいです。
きっかけは昨日こんなツイートをしたら割りとRTとFavがあったので、分かっている人には当たり前なのですが、解説を書いたらいいかなと思った次第です。
Pythonの人「for文を書いたら負け。ベクトル化して計算しろ。」
Juliaの人「ベクトル化して計算したら負け。for文書け。」
— (「・ω・)「ガオー (@bicycle1885) 2015, 4月 3Pythonのfor文
PythonやRを使っている人で、ある程度重い計算をする人達には半ば常識になっていることとして、いわゆる「for文を使ってはいけない。ベクトル化*1しろ。」という助言があります。 これは、PythonやRのようなインタープリター方式の処理系をもつ言語では、極めてfor文が遅いため、C言語やFortranで実装されたベクトル化計算を使うほうが速いという意味です。
まずはこれを簡単な例で検証してみましょう。
以下のように、ベクトルaとbの内積を計算するdot(a, b)という関数を考えてみます。
def dot(a, b): s = 0 for i in xrange(len(a)): s += a[i] * b[i] return s
これと同じ動作をする関数がNumPyには用意されており、こちらはPythonではなくより下のCPUに近いレベルでfor文を実行しています。 2つの大きさのベクトル(10要素と100,000要素)に対して、この2つの実装の速度の違いを検証してみました。
~/tmp $ ipython Python 2.7.9 (default, Feb 4 2015, 03:28:46) Type "copyright", "credits" or "license" for more information. IPython 3.0.0 -- An enhanced Interactive Python. ? -> Introduction and overview of IPython's features. %quickref -> Quick reference. help -> Python's own help system. object? -> Details about 'object', use 'object??' for extra details. In [1]: def dot(a, b): ...: s = 0 ...: for i in xrange(len(a)): ...: s += a[i] * b[i] ...: return s ...: In [2]: import numpy as np In [3]: a = np.ones(10) In [4]: b = np.ones(10) In [5]: dot(a, b) Out[5]: 10.0 In [6]: np.dot(a, b) Out[6]: 10.0 In [7]: timeit dot(a, b) The slowest run took 7.89 times longer than the fastest. This could mean that an intermediate result is being cached 100000 loops, best of 3: 4.32 µs per loop In [8]: timeit np.dot(a, b) The slowest run took 13.83 times longer than the fastest. This could mean that an intermediate result is being cached 1000000 loops, best of 3: 793 ns per loop In [9]: a = np.ones(100000) In [10]: b = np.ones(100000) In [11]: timeit dot(a, b) 10 loops, best of 3: 35.3 ms per loop In [12]: timeit np.dot(a, b) 10000 loops, best of 3: 51.9 µs per loop
Python実装とNumPy実装の速度差は歴然としています。 10要素の短いベクトルでも1桁の違いがあり、100,000要素では実に3桁もNumPyの方が速いことになります。
| 大きさ | Python | NumPy |
|---|---|---|
| 10 | 4.32μs | 793ns |
| 100,000 | 35.3ms | 51.9μs |
この違いは、たとえ大きな配列の確保などのオーバーヘッドがあったとしてもそれを相殺することができるほど大きく、 したがって、Pythonでは「for文を使ってはいけない。ベクトル化しろ。」というスローガンは正しいと言えます。
Juliaのfor文
では本題のJuliaの場合はどうでしょうか。Juliaでは、for文はC言語などと同じ速度で実行されるため、for文でループしても遅くはなりません。
ここでは、純粋なJuliaのコードと、JuliaからC言語を呼び出すコードを比較してみましょう。
C言語での実装は以下の通りです。
#include <stddef.h> double mydot(double* a, double* b, size_t len) { double s = 0; size_t i; for (i = 0; i < len; i++) s += a[i] * b[i]; return s; }
これを動的ライブラリとしてコンパイルしておきます。
~/tmp $ clang -dynamiclib -O3 -o libdot.dylib dot.c
Julia側の実装と、先のCのコードを呼び出す関数は以下のようになります。
function mydot(a, b)
s = 0.0
for i in 1:length(a)
s += a[i] * b[i]
end
s
end
function cmydot(a, b)
ccall((:mydot, "libdot"), Float64, (Ptr{Float64}, Ptr{Float64}, Csize_t), a, b, length(a))
end
これらの時間を計測してみましょう。
push!(LOAD_PATH, ".")
let
a = ones(10)
b = ones(10)
mydot(a, b)
cmydot(a, b)
println("mydot 10")
@time for _ in 1:1000; mydot(a, b); end
println("cmydot 10")
@time for _ in 1:1000; cmydot(a, b); end
a = ones(100_000)
b = ones(100_000)
println("mydot 100,000")
@time for _ in 1:1000; mydot(a, b); end
println("cmydot 100,000")
@time for _ in 1:1000; cmydot(a, b); end
end
これを実行してみると、幾分C言語のほうが速いようですが、Pythonのときに見られたほどの大きな差は得られません。
しかもこの差は、Juliaの@inboundsマクロを使えば消えてしまいます。
~/tmp $ julia for.jl mydot 10 elapsed time: 2.3714e-5 seconds (0 bytes allocated) cmydot 10 elapsed time: 9.407e-6 seconds (0 bytes allocated) mydot 100,000 elapsed time: 0.136645766 seconds (0 bytes allocated) cmydot 100,000 elapsed time: 0.112500924 seconds (0 bytes allocated)
これまでのことから、Juliaのfor文は十分高速で、「for文を使っても良い」ということが分かります。
Juliaでのベクトル化は遅い
ブログタイトルのスローガンは「Juliaではfor文を使え。ベクトル化してはいけない。」でした。 「for文を使っても良い」のは大丈夫として、では何故ベクトル化してはいけないのでしょうか。
この根本的な原因は、今のJulia(v0.3.7)には破壊的な演算子が無いため、いつでも新しい配列を確保してしまう点にあります。
この効果を見るため、拙作のANMS.jlパッケージのコードを見てみましょう。
# reflect
@inbounds for j in 1:n
xr[j] = c[j] + α * (c[j] - xh[j])
end
ここで、xr, c, xhは同じ長さのベクトルで、αはスカラーの係数です。
計算したいことは、二点cとxhの座標から点xrの座標を計算しているだけなのですが、これをNumPyの感覚でxr = c + α * (c - xh)と書いてしまうと、各演算子の適用の度(+, *, -で都合3回)に新たな配列が確保されることになります。これでは、配列の確保とGCが頻発し、パフォーマンスが要求されるコードでは大きな損失になります。
ですので、ここではベクトル化された+や*のような演算子は使えず、for文を書かざるを得なくなります。
もちろんNumPyでもこうした一次配列の確保は生じるのですが、Pythonではfor文があまりに遅いため、for文に書き換えると逆に遅くなってしまいます。
以上をもって、「Juliaではfor文を使え。ベクトル化してはいけない。」ということが実証されたことになります。
「早すぎる最適化は諸悪の根源である」
ただ、上に挙げたJuliaのベクトル化は、問題にならないことの方が多いです。 というのも、ほとんどのコードはプログラム全体から見るとボトルネックにはならず、したがってベクトル化計算をfor文に展開しても、得られる効果は殆ど無いに等しいものになります。 ですので、可読性や表記の簡便性から、Juliaにおいてもまずはベクトル化したコードを書き、ベンチマークによってそこがボトルネックになっていることが判明した時に初めてfor文を使って書き換えることが推奨されるのです。 Knuth先生の箴言を持って先のスローガンを修正するとすれば、「ボトルネックになっていることが確かめられたのなら、そこではfor文を使え。ベクトル化してはいけない。」となります。
参考
JuliaによるNelder-Meadアルゴリズムの実装
Optim.jlというJuliaの関数最適化パッケージの出力が気になったのでプルリクエストを投げたら、ちょっと議論になり色々Nelder-Meadアルゴリズムを調べる事になってしまい、その副作用で少し詳しくなったのでJuliaで実装を書いてみました。Optim.jlの実装より高速だと思います。そのパッケージがこちらです: ANMS - Adaptive Nelder-Mead Simplex Optimization
Nelder-Mead法というのは、ご存じの方はご存知のように、n変数の関数の最適化をする際にn+1点からなるsimplex(単体)を変形させながら最小値をgreedyに探索するアルゴリズムです。
アルゴリズム自体は1960年代がある古い古い方法で、数々の亜種が存在します。 今回実装したのはそのうちの比較的新しい Adaptive Nelder-Mead Simplex (ANMS) (Gao and Han, 2010) というものです。 これは、simplexの変形に関わるパラメータを関数の次元によって変えることで、より関数の評価回数が少なくて済むようになっています。 実装自体も最初のパラメータを次元に応じて変える以外はとくに特別なことはしていないため、とても簡単です。
詳細は元論文に譲りますが、simplexの変形は以下の5つからなります。
- Relection:
- Expansion:
- Contraction:
- Outside:
- Inside:
- Outside:
- Shrink:
ここで、 は最大値を取る頂点("h"igh)、
は最小値を取る頂点("l"ow)、
は最大値を取る頂点を除くsimplexの全頂点の平均("c"entroid)として定義されています。また、
は変形のパラメータになります。
各頂点の値によって、上の変形のうちのひとつを選択し、新しいsimplexとします。
それを繰り返すことで、徐々にsimplexを最小値付近に近づけて行き、ある収束条件や最大反復回数を満たしたところで終了とします。
そのsimplexの動きから、アメーバ法などと言われることもあります。

 Simplexの動きの図
Simplexの動きの図
ANMSでは、nを関数の次元として、変形のパラメータを以下のように取ります。
これらの次元に応じたパラメータにより、高次元の関数ではあまり効率的でない変形が起きにくいようになっています。
さらに、今回書いた実装では、
- simplexの頂点を関数値に応じてソートし、
や
など必要な頂点をすぐに取ってこれるようにしている
- shrink以外の変形では、1頂点のみしか移動しないため、平均
の計算を差分のみ行う
ようにして、高次元でさらに高速になるようにしています。
一気呵成に書き上げてまだよく検証していませんが、実装も200行ほどとコンパクトでコメントも多めに入れたので、効率的な実装の参考などにお役立て下さい。
https://github.com/bicycle1885/ANMS.jl/blob/master/src/ANMS.jl
参考
Juliaのコードを勝手に最適化してみた
こちらのスライドのパフォーマンスが気になったので、ちょっと速くしてみました。
気になったのはコレです。
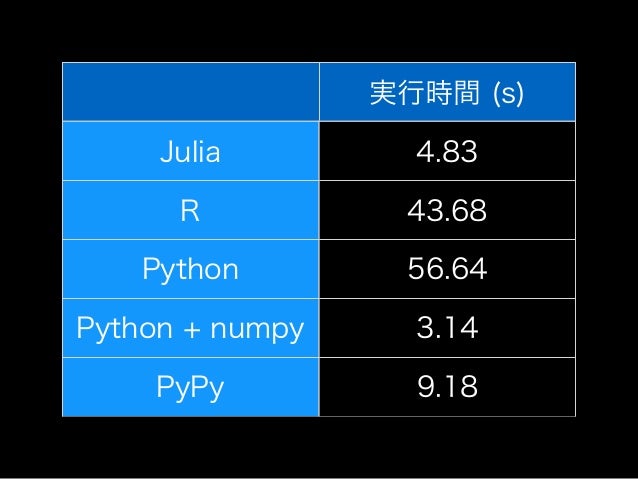
おかしいっ、我らがJuliaがPython + NumPyに負けるわけないっ。 早速いじってみましょう。
元コードはモンテカルロ法で円周率を計算する次のコードです。

写して実行してみると確かに5秒弱という感じでした。
pi0.jl
tic()
circle_in = 0.0
for i in 1:100000000
l = (rand()^2 + rand()^2) ^ 0.5
if l <= 1
circle_in = circle_in + 1
end
end
println(4 * circle_in / 100000000)
toc()
~/s/pi-opt $ julia pi0.jl 3.14189192 elapsed time: 4.653206114 seconds
ベンチマークは以下の環境で、3回実行しベストの値を示しています。
julia> versioninfo() Julia Version 0.3.3 Commit b24213b* (2014-11-23 20:19 UTC) Platform Info: System: Darwin (x86_64-apple-darwin13.4.0) CPU: Intel(R) Core(TM) i5-4288U CPU @ 2.60GHz WORD_SIZE: 64 BLAS: libopenblas (USE64BITINT DYNAMIC_ARCH NO_AFFINITY Haswell) LAPACK: libopenblas LIBM: libopenlibm LLVM: libLLVM-3.3
では早速色々と試してみましょう。
1. 関数化
Juliaの最適化は、トップレベルか否かでかなり気合が違います。トップレベルに書かれたコードはあまり最適化が効きません。なので、この計算全体を関数にするだけでかなり速くなることがあります。 試してみましょう。
pi1.jl
function calc_pi()
circle_in = 0.0
for i in 1:100000000
l = (rand()^2 + rand()^2) ^ 0.5
if l <= 1
circle_in = circle_in + 1
end
end
println(4 * circle_in / 100000000)
end
@time calc_pi()
~/s/pi-opt $ julia pi1.jl 3.14150504 elapsed time: 1.991970434 seconds (3423756 bytes allocated)
実装を関数でくるんだだけで、倍以上の速さになりましたね。これでPythonには負けないでしょう。
2. 0.5乗の排除
数値計算では0.5乗よりsqrt関数を使ったほうが速いでしょう。
JuliaがベースにしているLLVMにはllvm.sqrt命令がありますし、CPUによっては平方根の計算を効率的に処理できるかもしれません。
diff pi1.jl pi2.jl
--- pi1.jl 2015-01-04 17:08:01.000000000 +0900
+++ pi2.jl 2015-01-04 17:08:05.000000000 +0900
@@ -1,7 +1,7 @@
function calc_pi()
circle_in = 0.0
for i in 1:100000000
- l = (rand()^2 + rand()^2) ^ 0.5
+ l = sqrt(rand()^2 + rand()^2)
if l <= 1
circle_in = circle_in + 1
end
~/s/pi-opt $ julia pi2.jl 3.141662 elapsed time: 1.381137818 seconds (3386196 bytes allocated)
これだけでも幾分速くなりました。
3. 型合わせ
変数lの比較の両端で型が違うのが気になります。lはFloat64になりますが、Juliaではリテラル1はInt型です。
これを1.0とすることで型を合わせてみましょう。
細かすぎて伝わらないdiffですが、効果はあります。
diff pi2.jl pi3.jl
--- pi2.jl 2015-01-04 17:08:05.000000000 +0900
+++ pi3.jl 2015-01-04 17:35:36.000000000 +0900
@@ -2,8 +2,8 @@
circle_in = 0.0
for i in 1:100000000
l = sqrt(rand()^2 + rand()^2)
- if l <= 1
- circle_in = circle_in + 1
+ if l <= 1.
+ circle_in = circle_in + 1.
end
end
println(4 * circle_in / 100000000)
~/s/pi-opt $ julia pi3.jl 3.14178328 elapsed time: 1.236008727 seconds (3374932 bytes allocated)
0.1秒強の改善がありました。一応、足し込む方の+ 1も+ 1.に変えていますが、こちらの効果はあまり無いようでした。
4. 分岐排除
大量に繰り返すループの中で分岐は命取りです。これも削りましょう。
Juliaにはifelseという関数があり、簡単な計算ならこれで分岐を無くすことができます。
ifelseについてはid:yomichiさんの
ifelse() と関数の分離による高速化 -- Base.randn() を題材にして -- - yomichi's blog
が大変参考になります。
今回は1を足すか足さないかという単純な処理ですので、関数評価などのコストを掛けることなくifelseをつかって分岐をなくし効率化できることが期待されます。
diff pi3.jl pi4.jl
--- pi3.jl 2015-01-04 17:35:36.000000000 +0900
+++ pi4.jl 2015-01-04 17:39:37.000000000 +0900
@@ -2,9 +2,7 @@
circle_in = 0.0
for i in 1:100000000
l = sqrt(rand()^2 + rand()^2)
- if l <= 1.
- circle_in = circle_in + 1.
- end
+ circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
end
~/s/pi-opt $ julia pi4.jl 3.14181944 elapsed time: 0.824275847 seconds (3379000 bytes allocated)
1.24s => 0.82sと効果は劇的です。
5. sqrtの排除
よく考えたら1.0と大小比較をしているのでsqrtは要りません。一応これも排除してみましょう。
diff pi4.jl pi5.jl
--- pi4.jl 2015-01-04 17:39:37.000000000 +0900
+++ pi5.jl 2015-01-04 17:44:20.000000000 +0900
@@ -1,7 +1,7 @@
function calc_pi()
circle_in = 0.0
for i in 1:100000000
- l = sqrt(rand()^2 + rand()^2)
+ l = rand()^2 + rand()^2
circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
~/s/pi-opt $ julia pi5.jl 3.1415418 elapsed time: 0.803608532 seconds (3373236 bytes allocated)
う〜んあんまり速くなりません。これくらいだと実行の度に変わってしまう程度の変動分しかありません。 LLVMは1.0の二乗が1.0であることぐらいは知っていて最適化しているのかもしれませんね。
6. 2乗の排除
もしかしたらx^2よりx*xの方が速いかもしれません。
diff pi5.jl pi6.jl
--- pi5.jl 2015-01-04 17:44:20.000000000 +0900
+++ pi6.jl 2015-01-04 17:49:00.000000000 +0900
@@ -1,7 +1,8 @@
function calc_pi()
circle_in = 0.0
for i in 1:100000000
- l = rand()^2 + rand()^2
+ x, y = rand(), rand()
+ l = x*x + y*y
circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
~/s/pi-opt $ julia pi6.jl 3.14171304 elapsed time: 0.781361798 seconds (3363408 bytes allocated)
平均的には速くなっている気がしますが、効果はいまいちです。このへんが限界でしょうか。
まとめ
というわけで、4.65s => 0.78sと6倍近い高速化を達成出来ました。 Juliaの最適化は色々とコツが必要ですが、慣れると怪しいところがわかってきます。 最終的なコードは以下の様な感じです。
pi6.jl
function calc_pi()
circle_in = 0.0
for i in 1:100000000
x, y = rand(), rand()
l = x*x + y*y
circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
end
@time calc_pi()