JuliaによるNelder-Meadアルゴリズムの実装
Optim.jlというJuliaの関数最適化パッケージの出力が気になったのでプルリクエストを投げたら、ちょっと議論になり色々Nelder-Meadアルゴリズムを調べる事になってしまい、その副作用で少し詳しくなったのでJuliaで実装を書いてみました。Optim.jlの実装より高速だと思います。そのパッケージがこちらです: ANMS - Adaptive Nelder-Mead Simplex Optimization
Nelder-Mead法というのは、ご存じの方はご存知のように、n変数の関数の最適化をする際にn+1点からなるsimplex(単体)を変形させながら最小値をgreedyに探索するアルゴリズムです。
アルゴリズム自体は1960年代がある古い古い方法で、数々の亜種が存在します。 今回実装したのはそのうちの比較的新しい Adaptive Nelder-Mead Simplex (ANMS) (Gao and Han, 2010) というものです。 これは、simplexの変形に関わるパラメータを関数の次元によって変えることで、より関数の評価回数が少なくて済むようになっています。 実装自体も最初のパラメータを次元に応じて変える以外はとくに特別なことはしていないため、とても簡単です。
詳細は元論文に譲りますが、simplexの変形は以下の5つからなります。
- Relection:
- Expansion:
- Contraction:
- Outside:
- Inside:
- Outside:
- Shrink:
ここで、 は最大値を取る頂点("h"igh)、
は最小値を取る頂点("l"ow)、
は最大値を取る頂点を除くsimplexの全頂点の平均("c"entroid)として定義されています。また、
は変形のパラメータになります。
各頂点の値によって、上の変形のうちのひとつを選択し、新しいsimplexとします。
それを繰り返すことで、徐々にsimplexを最小値付近に近づけて行き、ある収束条件や最大反復回数を満たしたところで終了とします。
そのsimplexの動きから、アメーバ法などと言われることもあります。

 Simplexの動きの図
Simplexの動きの図
ANMSでは、nを関数の次元として、変形のパラメータを以下のように取ります。
これらの次元に応じたパラメータにより、高次元の関数ではあまり効率的でない変形が起きにくいようになっています。
さらに、今回書いた実装では、
- simplexの頂点を関数値に応じてソートし、
や
など必要な頂点をすぐに取ってこれるようにしている
- shrink以外の変形では、1頂点のみしか移動しないため、平均
の計算を差分のみ行う
ようにして、高次元でさらに高速になるようにしています。
一気呵成に書き上げてまだよく検証していませんが、実装も200行ほどとコンパクトでコメントも多めに入れたので、効率的な実装の参考などにお役立て下さい。
https://github.com/bicycle1885/ANMS.jl/blob/master/src/ANMS.jl
参考
Juliaのコードを勝手に最適化してみた
こちらのスライドのパフォーマンスが気になったので、ちょっと速くしてみました。
気になったのはコレです。
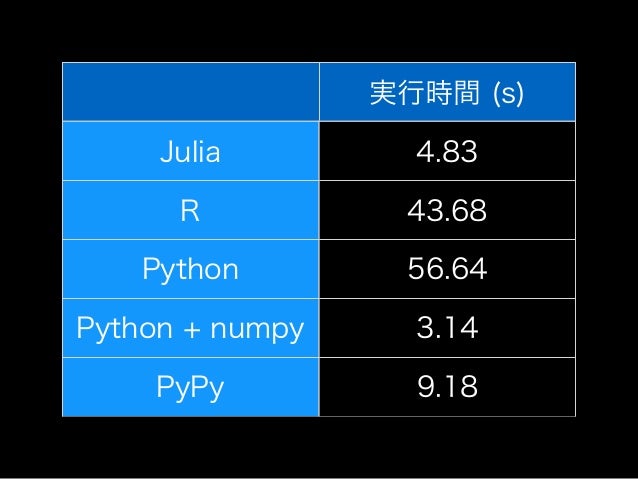
おかしいっ、我らがJuliaがPython + NumPyに負けるわけないっ。 早速いじってみましょう。
元コードはモンテカルロ法で円周率を計算する次のコードです。

写して実行してみると確かに5秒弱という感じでした。
pi0.jl
tic()
circle_in = 0.0
for i in 1:100000000
l = (rand()^2 + rand()^2) ^ 0.5
if l <= 1
circle_in = circle_in + 1
end
end
println(4 * circle_in / 100000000)
toc()
~/s/pi-opt $ julia pi0.jl 3.14189192 elapsed time: 4.653206114 seconds
ベンチマークは以下の環境で、3回実行しベストの値を示しています。
julia> versioninfo() Julia Version 0.3.3 Commit b24213b* (2014-11-23 20:19 UTC) Platform Info: System: Darwin (x86_64-apple-darwin13.4.0) CPU: Intel(R) Core(TM) i5-4288U CPU @ 2.60GHz WORD_SIZE: 64 BLAS: libopenblas (USE64BITINT DYNAMIC_ARCH NO_AFFINITY Haswell) LAPACK: libopenblas LIBM: libopenlibm LLVM: libLLVM-3.3
では早速色々と試してみましょう。
1. 関数化
Juliaの最適化は、トップレベルか否かでかなり気合が違います。トップレベルに書かれたコードはあまり最適化が効きません。なので、この計算全体を関数にするだけでかなり速くなることがあります。 試してみましょう。
pi1.jl
function calc_pi()
circle_in = 0.0
for i in 1:100000000
l = (rand()^2 + rand()^2) ^ 0.5
if l <= 1
circle_in = circle_in + 1
end
end
println(4 * circle_in / 100000000)
end
@time calc_pi()
~/s/pi-opt $ julia pi1.jl 3.14150504 elapsed time: 1.991970434 seconds (3423756 bytes allocated)
実装を関数でくるんだだけで、倍以上の速さになりましたね。これでPythonには負けないでしょう。
2. 0.5乗の排除
数値計算では0.5乗よりsqrt関数を使ったほうが速いでしょう。
JuliaがベースにしているLLVMにはllvm.sqrt命令がありますし、CPUによっては平方根の計算を効率的に処理できるかもしれません。
diff pi1.jl pi2.jl
--- pi1.jl 2015-01-04 17:08:01.000000000 +0900
+++ pi2.jl 2015-01-04 17:08:05.000000000 +0900
@@ -1,7 +1,7 @@
function calc_pi()
circle_in = 0.0
for i in 1:100000000
- l = (rand()^2 + rand()^2) ^ 0.5
+ l = sqrt(rand()^2 + rand()^2)
if l <= 1
circle_in = circle_in + 1
end
~/s/pi-opt $ julia pi2.jl 3.141662 elapsed time: 1.381137818 seconds (3386196 bytes allocated)
これだけでも幾分速くなりました。
3. 型合わせ
変数lの比較の両端で型が違うのが気になります。lはFloat64になりますが、Juliaではリテラル1はInt型です。
これを1.0とすることで型を合わせてみましょう。
細かすぎて伝わらないdiffですが、効果はあります。
diff pi2.jl pi3.jl
--- pi2.jl 2015-01-04 17:08:05.000000000 +0900
+++ pi3.jl 2015-01-04 17:35:36.000000000 +0900
@@ -2,8 +2,8 @@
circle_in = 0.0
for i in 1:100000000
l = sqrt(rand()^2 + rand()^2)
- if l <= 1
- circle_in = circle_in + 1
+ if l <= 1.
+ circle_in = circle_in + 1.
end
end
println(4 * circle_in / 100000000)
~/s/pi-opt $ julia pi3.jl 3.14178328 elapsed time: 1.236008727 seconds (3374932 bytes allocated)
0.1秒強の改善がありました。一応、足し込む方の+ 1も+ 1.に変えていますが、こちらの効果はあまり無いようでした。
4. 分岐排除
大量に繰り返すループの中で分岐は命取りです。これも削りましょう。
Juliaにはifelseという関数があり、簡単な計算ならこれで分岐を無くすことができます。
ifelseについてはid:yomichiさんの
ifelse() と関数の分離による高速化 -- Base.randn() を題材にして -- - yomichi's blog
が大変参考になります。
今回は1を足すか足さないかという単純な処理ですので、関数評価などのコストを掛けることなくifelseをつかって分岐をなくし効率化できることが期待されます。
diff pi3.jl pi4.jl
--- pi3.jl 2015-01-04 17:35:36.000000000 +0900
+++ pi4.jl 2015-01-04 17:39:37.000000000 +0900
@@ -2,9 +2,7 @@
circle_in = 0.0
for i in 1:100000000
l = sqrt(rand()^2 + rand()^2)
- if l <= 1.
- circle_in = circle_in + 1.
- end
+ circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
end
~/s/pi-opt $ julia pi4.jl 3.14181944 elapsed time: 0.824275847 seconds (3379000 bytes allocated)
1.24s => 0.82sと効果は劇的です。
5. sqrtの排除
よく考えたら1.0と大小比較をしているのでsqrtは要りません。一応これも排除してみましょう。
diff pi4.jl pi5.jl
--- pi4.jl 2015-01-04 17:39:37.000000000 +0900
+++ pi5.jl 2015-01-04 17:44:20.000000000 +0900
@@ -1,7 +1,7 @@
function calc_pi()
circle_in = 0.0
for i in 1:100000000
- l = sqrt(rand()^2 + rand()^2)
+ l = rand()^2 + rand()^2
circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
~/s/pi-opt $ julia pi5.jl 3.1415418 elapsed time: 0.803608532 seconds (3373236 bytes allocated)
う〜んあんまり速くなりません。これくらいだと実行の度に変わってしまう程度の変動分しかありません。 LLVMは1.0の二乗が1.0であることぐらいは知っていて最適化しているのかもしれませんね。
6. 2乗の排除
もしかしたらx^2よりx*xの方が速いかもしれません。
diff pi5.jl pi6.jl
--- pi5.jl 2015-01-04 17:44:20.000000000 +0900
+++ pi6.jl 2015-01-04 17:49:00.000000000 +0900
@@ -1,7 +1,8 @@
function calc_pi()
circle_in = 0.0
for i in 1:100000000
- l = rand()^2 + rand()^2
+ x, y = rand(), rand()
+ l = x*x + y*y
circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
~/s/pi-opt $ julia pi6.jl 3.14171304 elapsed time: 0.781361798 seconds (3363408 bytes allocated)
平均的には速くなっている気がしますが、効果はいまいちです。このへんが限界でしょうか。
まとめ
というわけで、4.65s => 0.78sと6倍近い高速化を達成出来ました。 Juliaの最適化は色々とコツが必要ですが、慣れると怪しいところがわかってきます。 最終的なコードは以下の様な感じです。
pi6.jl
function calc_pi()
circle_in = 0.0
for i in 1:100000000
x, y = rand(), rand()
l = x*x + y*y
circle_in += ifelse(l <= 1., 1., 0.)
end
println(4 * circle_in / 100000000)
end
@time calc_pi()
PythonistaのためのJulia100問100答
この記事はJulia Advent Calendar 2014の12日目の記事だったはずのものです(遅れてすいません...)。 Pythonユーザーとしての自分に対して100問100答形式で気になるだろうことを列挙したものになっています。
全体は以下の様なセクションに分かれています。
Juliaのバージョンはv0.3系を基本としていますが、開発中のv0.4の内容も必要に応じてコメントしています。
Julia
Juliaってどういう言語なの?
Juliaは高レベルでハイパフォーマンスな技術計算のための動的言語だよ。 構文はPythonユーザーならすぐに理解できるよ。
公式ウェブページはここ: http://julialang.org/
誰が作ってるの?
主にMITの人達が中心になって作ってる言語だよ。 特にJeff Bezansonという人が創始者のひとりで、一番コミットしてる人だよ。
ライセンスはどうなってるの?
Juliaの処理系自体はMIT Licenseだよ。 外部のライブラリや一部のソースコードに一部他のライセンスが適用されているよ。 詳しくはLICENSE.mdを見てね。
Juliaって速いの?
とっても速いよ!
ここで他の言語との比較ベンチマークが見られるからのぞいてみてごらん。 CやFortranのような言語と比べても決して遜色ないし、きっと動的型付け言語としては最速クラスだと思うよ!
何で速いの?
LLVMベースのJITコンパイラを搭載してるからだよ。 C言語みたいにビルドとか要らないし、インタープリタをつかうPythonと同じ感覚で簡単に動かせるよ。
PythonにもCythonとかあるけど?
「いやCythonとか面倒やろ、ていうかね、なんで別の言語使わないとあかんねんと。一つの言語でパフォーマンスが要求されるコアの部分からインターフェースまで書く、そういう考え方もできると思うんですよ。だって考えてみてくださいよ、ブラジルの選手Cython書かないでしょ。」
PyPyもあるけど?
最適化の仕方が多分かなり違うから、コードによってはJuliaのほうがずっと速かったりするよ。
Numbaもあるよね?
そうだね!
速度比較できるコード例はある?
大分極端な差が出るパフォーマンス比較だと、Nクイーン問題を解いた以下の例があるよ。
| N | Julia v0.4.0dev | CPython 2.7.8 | PyPy 2.4.0 |
|---|---|---|---|
| 11 | 0.0285 | 2.34 | 0.99 |
| 12 | 0.164 | 13.9 | 4.80 |
| 13 | 1.02 | - | 29.47 |
(単位は秒, 2.6GHz Intel Core i5, Mac OS X 10.9.5)
なお、測定にはJuliaは@timeマクロ、CPythonはIPythonのtimeit、PyPyはtimeitが正しく動かないのでrun -tでスクリプトを実行してWall timeを計測したよ。
PyPyには少し不利な測定方法だけど、それでもJuliaがすごく速いね!
function solve(n::Int)
places = zeros(Int, n)
search(places, 1, n)
end
function search(places, i, n)
if i == n + 1
return 1
end
s = 0
@inbounds for j in 1:n
if isok(places, i, j)
places[i] = j
s += search(places, i + 1, n)
end
end
s
end
function isok(places, i, j)
qi = 1
@inbounds for qj in places
if qi == i
break
elseif qj == j || abs(qi - i) == abs(qj - j)
return false
end
qi += 1
end
true
end
def solve(n): places = [-1] * n return search(places, 0, n) def search(places, i, n): if i == n: return 1 s = 0 for j in range(n): if isok(places, i, j): places[i] = j s += search(places, i + 1, n) return s def isok(places, i, j): for qi, qj in enumerate(places): if qi == i: break elif qj == j or abs(qi - i) == abs(qj - j): return False return True
環境
Juliaのレポジトリはどこ?
GitHubにホスティングされてるよ: https://github.com/JuliaLang/julia
インストールはJulia環境構築 2014 ver. #julialangを参考にしてね。
IPythonみたいなのはあるの?
コンソールではJuliaのREPLはわりと強力だよ。
juliaコマンドでREPLを立ち上げて、?と入力すると関数のドキュメントも参照できるし、;と入力するとシェルコマンドも実行できるすぐれものだよ!
タブ補完もあるし、Bashのような履歴機能もあるし、色も着くし、さらに全てJulia自身で実装されているんだよ!
あとIPython Notebookを使えるIJuliaというのもあるよ。
それにJupyterプロジェクトのJuはJuliaのJuだよ。
EmacsとかVimのサポートはあるの?
Emacsはjulia-mode.elが本体で開発されているよ。 Vimはjulia-vimというプラグインがあるよ。
あとはLightTable用のJunoとか、Sublime Textのためのパッケージもあるよ。
PyPIみたいなパッケージのレポジトリはあるの?
パッケージの管理はJuliaの機能にそもそも組み込まれているよ。 パッケージはhttp://pkg.julialang.org/で探せるよ。 このパッケージ管理はMETADATA.jlというメタパッケージを通して行われてるんだ。
どうやってパッケージをインストールするの?
JuliaのREPLを立ち上げてPkg.add("PackageName")などとするとMETADATA.jlに登録されているパッケージはインストールできるよ。
他にはシェルから直接
julia -e 'Pkg.add("PackageName")'
としてもOKだよ。
METADATA.jlにはないけどGitHubなどにホスティングされているGitレポジトリなら、Pkg.addの代わりにPkg.cloneにGitレポジトリのURLを渡すとインストールできるよ。
PEP8みたいなスタイルの規範はあるの?
きっちりこれに従わなければ村八分というのはないけど、ゆるい慣習としてドキュメントに記載されているのは、
- 変数名は小文字
- 単語の境界はアンダースコア(
_)。でもなるべく使用は避ける。 - 型名は大文字で始まり、CamelCase
- 関数名やマクロ名は小文字でアンダースコアなし。
- 引数を破壊的に変更する関数は
!をつける(sort!など)。
だよ。
他に標準ライブラリを読むと、
- スペース4つでインデント
- オペレータの左右にはスペース(✖:
x+y, ✔:x + y) - ただし配列のインデックスではスペースを空けない(
1:n-3など)
といったルールに従ってるっぽいかな。
う〜んPythonを呼び出したいなぁ...
実はPyCall.jlなんていうPythonを呼び出せるライブラリもあるよ。 かなりちゃんと動くよ!
今度はC++を...
まだ若いけどCxx.jlがかなり期待できそうだよ。 他にはC++をCでラップして呼び出す方法もあるよ。
データ
TrueとFalseは?
小文字化したtrueとfalseがあるよ。
数値は?
基本Pythonと同じように42と書くと整数、42.0とかくと浮動小数点数になるよ。
Noneは?
nothingがそれに当たるよ。
演算子はどんな感じ?
+, -, *はPythonと同じ感じ。でも/はPython2でなくPython3と同じように整数 / 整数が浮動小数点数になるので気をつけてね。
julia> 10 / 2 5.0 julia> 3 / 2 1.5
Python2の/に当たるのはJuliaではdiv関数だよ。
julia> div(10, 2) 5 julia> div(3, 2) 1
andやorは?
JuliaではC言語と同様に&&や||を使うよ。
Pythonのlistやdictにあたるのは何?
PythonのlistはJuliaのVector{T}型に、dictはDict{K,V}型が対応してるよ。
そのVector{T}のTとかDict{K,V}のKとかVとかは何?
型パラメータ(type parameter)だよ。Vector{T}ならそのベクターはT型の要素を持っていて、Dict{K,V}はK型が辞書のキーでVが値の型だよ。
例えばVector{Int64}なら(符号付き)64bitの整数が要素のベクターだし、Dict{ASCIIString,Bool}ならASCII文字列がキーでブール値が値の辞書だよ。
type関数みたいにある値の型の確認するのはどうするの?
typeof関数を使おう。
julia> typeof(1)
Int64
julia> typeof(1.0)
Float64
julia> typeof([1,2,3])
Array{Int64,1}
julia> typeof("foobar")
ASCIIString (constructor with 2 methods)
julia> typeof("漢字とか")
UTF8String (constructor with 2 methods)
Vectorのインデックス0の要素にアクセスしようとしたらエラーがでたんだけど!?
そうそう、Juliaではインデックスは1始まりだよ。
xrangeはあるの?
範囲型ももちろんあるよ!例えばPythonのxrange(0, 10)はJuliaだと0:9と書くよ。
Pythonと違って範囲の右端が含まれることに注意してね!
dictは?
Dict{K,V}という型があるよ。Kがキーの型でVが値の型だよ。
julia> d = Dict{ASCIIString,Int}()
Dict{ASCIIString,Int64} with 0 entries
julia> d["foo"] = 100
100
julia> d["bar"] = 200
200
julia> d["bar"]
200
julia> haskey(d, "foo")
true
julia> haskey(d, "baz")
false
tupleは?
あるよあるよ!Pythonと同じようにコンマ(,)をつかって作れるよ!
julia> 1, 1.0, "one" (1,1.0,"one") julia> (1, 1.0, "one") (1,1.0,"one")
Pythonのタプルとの違いはタプルはその要素によって型が別々なところかな。
julia> typeof((1, 1.0, "one")) (Int64,Float64,ASCIIString) julia> typeof((1, "壱")) (Int64,UTF8String)
関数も引数として渡したりできるの?
もちろん! Juliaでは関数もFunctionという型のオブジェクトだよ。
lambda式みたいな無名関数は?
->という矢印を使うと作れるよ。
julia> x -> x * 10
(anonymous function)
julia> map(x -> x * 10, [1,2,3])
3-element Array{Int64,1}:
10
20
30
julia> typeof(x -> x * 10)
Function
日付・時刻を表すdatetimeみたいなのは?
v0.4からDateTime型が入るよ!
http://julia.readthedocs.org/en/latest/stdlib/dates/
もっとPythonの型との対応関係を教えて!
はいよ!
ちなみにPython2系を基準にしてるよ。
| Python | Julia | 備考 |
|---|---|---|
| NoneType | Nothing | v0.4からはVoid |
| bool | Bool | |
| int | Int | IntがInt32かInt64かは環境依存 |
| float | Float64 | |
| str | ASCIIString | |
| unicode | UnicodeString | |
| dict | Dict{K,V} | |
| list | Vector{T} | |
| bytearray | Vector{Uint8} | v0.4からは Vector{UInt8} |
| tuple | (T1,), (T1,T2), (T1,T2,T3), ... | |
| set | Set{T} / IntSet | |
| xrange | UnitRange{T} / StepRange{T,S} | 浮動小数点数などの範囲型もある |
| datetime | DateTime | v0.4から |
| module | Module | |
| type | DataType | |
| Exception | Exception | 抽象型 |
技術計算
NumPyとかSciPyみたいなのが使いたいんだけど?
Juliaは技術計算のための言語を目的としてるから、標準ライブラリとして多くが組み込まれているよ。
NumPyのndarrayはどれ?
Array{T,N}という多次元配列があるよ。
実はさっきのVector{T}はArray{T,1}という1次元配列のエイリアスだよ。
NumPyみたいなベクトル化の計算もできるの?
もちろん!
+はArrayに対しても定義されてるからね。
要素ごとの加算であることを明確にするため.+という演算子もあるよ。
julia> x = [1,2,3]
3-element Array{Int64,1}:
1
2
3
julia> y = [4,5,6]
3-element Array{Int64,1}:
4
5
6
julia> x + y
3-element Array{Int64,1}:
5
7
9
julia> x .+ y
3-element Array{Int64,1}:
5
7
9
空の配列をつくるときは?
Array型のコンストラクタを呼ぶと目的の型の配列を作ってくれるよ。
呼び出し方はArray(<型名>, <サイズのタプル>)だよ。
初期化されてないこともあるから注意してね。
julia> Array(Int, (2, 3))
2x3 Array{Int64,2}:
140339717649152 140339717659744 140339700672608
140339719760256 140339700672608 0
julia> Array(Int, (2, 3, 4))
2x3x4 Array{Int64,3}:
[:, :, 1] =
0 0 0
0 0 0
[:, :, 2] =
0 0 0
0 0 0
[:, :, 3] =
0 0 0
0 0 0
[:, :, 4] =
0 0 0
0 0 0
julia> Array(Float64, (10, 10))
10x10 Array{Float64,2}:
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
配列の初期化をしたいんだけど?
fill!を使ってね。
!がついてる関数は破壊的なので元の配列に直接書き込むよ。
julia> x = Array(Float64, (3, 3))
3x3 Array{Float64,2}:
6.95286e-310 6.95285e-310 0.0
6.95285e-310 0.0 0.0
6.95286e-310 0.0 0.0
julia> fill!(x, 0.5)
3x3 Array{Float64,2}:
0.5 0.5 0.5
0.5 0.5 0.5
0.5 0.5 0.5
julia> x
3x3 Array{Float64,2}:
0.5 0.5 0.5
0.5 0.5 0.5
0.5 0.5 0.5
非破壊版のfillもあるよ。
0や1で埋められた配列はどうつくるの?
zerosやonesや関数があるよ。
julia> zeros(3, 3)
3x3 Array{Float64,2}:
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
julia> zeros((3, 3))
3x3 Array{Float64,2}:
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
julia> zeros(Int, 3, 3)
3x3 Array{Int64,2}:
0 0 0
0 0 0
0 0 0
julia> ones(3, 3)
3x3 Array{Float64,2}:
1.0 1.0 1.0
1.0 1.0 1.0
1.0 1.0 1.0
scipy.sparseみたいな疎行列が欲しいなぁ?
SparseMatrixCSCがあるよ!
spzerosでゼロ初期化された疎行列を作れるよ。
試しに10,000 x 10,000行列を作ってみよう。
julia> x = spzeros(10000, 10000)
10000x10000 sparse matrix with 0 Float64 entries:
julia> x[rand(1:10000, 3), rand(1:10000, 3)] = randn(9)
9-element Array{Float64,1}:
0.273565
0.982527
0.469546
-0.132561
0.49318
-0.59534
-0.403649
-0.748683
0.819549
julia> x
10000x10000 sparse matrix with 9 Float64 entries:
[1564 , 858] = 0.819549
[4492 , 858] = -0.748683
[7057 , 858] = -0.403649
[1564 , 4839] = -0.59534
[4492 , 4839] = 0.49318
[7057 , 4839] = -0.132561
[1564 , 9154] = 0.469546
[4492 , 9154] = 0.982527
[7057 , 9154] = 0.273565
scipy.statsでやるみたいに確率分布からサンプリングしたいんだけど?
Distributions.jlがあるよ。
線形方程式系が解きたいんだけど?
\\という演算子があるよ。
例えば、Ax = yという方程式を解くなら以下の様な感じだよ。
julia> A = [1.0 2.0; 2.0 3.0]
2x2 Array{Float64,2}:
1.0 2.0
2.0 3.0
julia> y = [5.0, 8.0]
2-element Array{Float64,1}:
5.0
8.0
julia> A \ y
2-element Array{Float64,1}:
1.0
2.0
LU分解とかQR分解とかSVDとか固有値とか行列式とか...
ここを見て! http://julia.readthedocs.org/en/latest/stdlib/linalg/
言語機能
defみたいな関数定義の方法は?
function ... endで関数が定義できるよ。
例えばn番目のフィボナッチ数の計算をするfib(n)なら、
function fib(n)
if n < 2
return 1
else
return fib(n - 1) + fib(n - 2)
end
end
という感じ。ちなみにreturnは省略可能なので省略されることも多いよ。
もう一つの記法として、
fib(n) = n < 2 ? 1 : fib(n - 1) + fib(n - 2)
というように一行で定義することもできるよ。
引数の型を制限するために、
function fib(n::Integer)
# ...
end
というように::<型>を引数につけられるよ。
可変長引数は?
args...というように仮引数に...をつけると使えるよ。
function foo(x, y, zs...)
println("x: $x")
println("y: $y")
println("zs: $zs")
end
これを使ってみると、
julia> foo(1, 2) x: 1 y: 2 zs: () julia> foo(1, 2, 3) x: 1 y: 2 zs: (3,) julia> foo(1, 2, 3, 4) x: 1 y: 2 zs: (3,4) julia> foo(1, 2, 3, 4, 5) x: 1 y: 2 zs: (3,4,5)
と言ったかんじ。
可変長引数の展開も同じように...をつけるんだよ。
julia> zs = [3, 4, 5]
3-element Array{Int64,1}:
3
4
5
julia> foo(1, 2, zs...)
x: 1
y: 2
zs: (3,4,5)
オプション引数やキーワード引数は?
もちろん使えるよ!
オプション引数:
function foo(x, y=1, z=2)
println("x: $x")
println("y: $y")
println("z: $z")
end
使用例:
julia> foo(0) x: 0 y: 1 z: 2 julia> foo(0, 100) x: 0 y: 100 z: 2 julia> foo(0, 100, 200) x: 0 y: 100 z: 200
キーワード引数:
function foo(x; y=1, z=2)
println("x: $x")
println("y: $y")
println("z: $z")
end
使用例:
julia> foo(0, y=1, z=2) x: 0 y: 1 z: 2 julia> foo(0, z=1, y=2) x: 0 y: 2 z: 1
Pythonの変数スコープと違いはある?
簡潔に列挙していくと
- 関数定義がスコープをつくるのは同じ
- 現在のスコープでで変数が定義されてないときに外側に探しに行き、最終的にグローバルスコープに行くのも同じ
ifがスコープを作らないのも同じ- でも、Juliaの
forやwhileといったループがスコープをつくるのが違う - Juliaでは
tryもスコープをつくる - 内包表記で使われる変数はPython2と違ってその内包表記内のみのスコープになる(これはPython3と同じ)
forを例に具体的動作の違いを見てみよう。
まずはPythonの動作の確認から。
In [1]: for i in xrange(10): ...: x = i ...: In [2]: x Out[2]: 9
このようにfor文内で定義したxにはfor文を抜けた後もアクセスできるね。
これをJulia側で見てみると、
julia> for i in 0:9
x = i
end
julia> x
ERROR: x not defined
というように、変数xにはアクセスできなくなっているよ。
じゃぁJuliaで変数の値をループ内で設定したいときはどうするのさ
localを使おう!
次のようにlocal xと書くことでPythonと同様の動作を実現できるよ。
julia> function foo()
local x
for i in 0:9
x = i
end
x
end
foo (generic function with 1 method)
julia> foo()
9
クラスを定義したいんだけど?
新しいデータ型を定義するには、type...endとimmutable...endの2つの定義の仕方があるよ。
例えば、
type Point
x::Float64
y::Float64
end
immutable IPoint
x::Float64
y::Float64
end
のように同じように定義できて、immutableの方はメンバーの変更ができないよ。
コンストラクタ(__init__)はどうやって定義するの?
デフォルトのコンストラクタがあるから自分で定義しなくてもオブジェクトは作れるよ。
p1 = Point(1.2, 3.4) print(p1)
もちろん自分でも定義できるよ!
型名と同名の関数を以下のように定義して、内部でnewを呼べばOKだよ。
type Point
x::Float64
y::Float64
function Point(x, y)
if x >= y
error("x should be less than y")
end
new(x, y)
end
end
isinstance関数に当たるのは?
isaがあるよ。
julia> isa(1, Int)
true
julia> isa(1, Integer)
true
julia> isa(1, Float64)
false
julia> isa("string", ASCIIString)
true
julia> isa("string", String) # v0.4からはAbstractString
true
クラスの継承は?
できないよ。
ほんとに?
う〜ん。近しいものとしてnominal subtypingといって抽象型(abstract type)の下に具体型(concrete type)を定義して型の階層関係を定義できるよ。 注意しなければいけないのは具体型のsubtypeとして具体型を定義することはできない点だよ。
例えばこんな感じ:
abstract Person
type Employer <: Person
name::UTF8String
age::Int
end
type Employee <: Person
name::UTF8String
age::Int
salary::Int
end
ちなみに<:はある型が別の型のサブタイプかどうかを調べる演算子としても使えるよ。
次の例ではInt, Int8, Float64が具体型でIntegerとFloatingPointが抽象型だよ。
julia> Int <: Integer true julia> Int8 <: Integer true julia> Float64 <: FloatingPoint true julia> Int <: FloatingPoint false
それって将来変わるの?
構造を継承するような変更は入らないと思うよ。
マニュアルから引用すると:
While this might at first seem unduly restrictive, it has many beneficial consequences with surprisingly few drawbacks. It turns out that being able to inherit behavior is much more important than being able to inherit structure, and inheriting both causes significant difficulties in traditional object-oriented languages.
さらにStefan Karpinski氏の言葉を引用すると:
There are never going to be classes in Julia in the C++/Java style. This is by design. Inheriting structure — i.e. tacking fields onto a composite object type — is rarely of much use and has huge downsides. There are two types of sharing that inheritance is suposed to be useful for: sharing structure and sharing behavior. If you want to share structure, delegation is a much better design than tacking extra fields onto a existing composite type. If you want to share behavior, then a better design is to write generic code to an abstract type (a.k.a. a trait in OO lingo) of which the concrete types are specific implementations. To those ends, we probably need some features to improve delegation support, as well as support for multiple inheritance from abstract types. Class-based OO, however, is definitely never going to happen.
https://groups.google.com/forum/#!msg/julia-dev/p9bV6rMSmvY/cExeSb-cMBYJ
つまり、型のメンバ(フィールド)を共有させるような機能よりは振る舞いを共有させるほうが重要だし、移譲を使えば別にフィールドを共有させる必要はないよねということだよ。
さっきの例なら:
type Person
name::UTF8String
age::Int
end
type Employer
person::Person
end
type Employee
person::Person
salary::Int
end
としてもいいよね。
文字列の長さを取得したいんだけど、lenみたいなのはあるの?
length関数があるよ。
> length("foobar")
6
> length("日本語")
3
自分で定義した型にlenを使いたいんだけど、__len__みたいなメソッドはあるの?
自分で定義した型にlengthメソッドを定義してやるだけだよ。
やり方は簡単で、自分の定義した型Fooに対してはlength(foo::Foo)というメソッドを以下のように定義できるよ。
例えばA,C,G,Tの四文字だけを持つ文字列DNAStringを圧縮して効率的に保持することを考えると、以下のように定義できるよ。
type DNAString
n::Int
pack::Vector{Uint8}
function DNAString(s::ASCIIString)
...
end
end
function length(s::DNAString)
s.n
end
え、それはlength以外でもできるの?
そう!それがJuliaの多重ディスパッチング(multiple dispatch)だよ!
「多重」ってのはどういうこと?
複数の引数があっても、その型の組み合わせで実際に呼び出されるメソッドが決まるということだよ。
それはどんなところで役に立つの?
例えばPythonでmodel.predict(data)のように与えられたモデルでデータの予測をしようとしたときを考えてみよう。
ここで引数として与えられるdataの型はlistかもしれないし、NumPyのndarrayかもしれないとする。
Pythonだと
class SomeModel: ... def predict(self, data): if isinstance(data, list): self.predict_list(list) elif instance(data, np.ndarray): self.predict_array(data)
のようにSomeModel.predictメソッド内で自分で分岐をするコードを書くことになっちゃうけど、Juliaだと
predict(model::SomeModel, data::List)
...
end
predict(model::SomeModel, data::Array)
...
end
というようにメソッドの定義自体を分離して書けるんだ!
__getitem__メソッドは?
getindexがあるよ。
他の特殊メソッドの対応関係は?
こんな感じかな?
| Python | Julia | 備考 |
|---|---|---|
__getitem__ |
getindex |
|
__setitem__ |
setindex! |
|
__delitem__ |
delete! |
|
__lt__ |
isless / < |
islessは全順序、<は半順序 |
__eq__ |
==/isequal |
浮動小数点数ではisequalと振る舞いが異なる |
__contains__ |
in |
|
__hash__ |
hash |
|
__call__ |
call |
v0.4から |
__str__ |
show |
|
__len__ |
length |
空のコンテナにFalseを返すような__nonzero__(__bool__)を定義したいんだけど?
Juliaは割りと暗黙の意味みたいなのを嫌うのでそういうのはないよ。
bool関数はあるけど数値のみに定義されていてPythonみたいに文字列などには定義されてないよ。
じゃぁどうするの?
isemptyとか明示的な関数を使おう!
JuliaでBool値を返す関数はis___という名前を持っていて、
ほかにもisnan, isspace, isalpha, islower, isupperなどたくさんあるよ!
イテレータを定義したいな
Juliaのイテレータはstart, done, nextの3つの関数からなるので、これを自分の定義した型にも定義してあげるといいよ。
start(iter) → stateで開始状態を設定しdone(iter,state) → Boolで状態を受けてイテレーションが終了したか否かを返しnext(iter,state) → item,stateで要素と次の状態を返すんだ。
イテレータIに対するfor文
for i in I
# body
end
は以下のものと等価になるんだ。
state = start(I)
while !done(I, state)
(i, state) = next(I, state)
# body
end
試しにTODOリストの未完了のタスクに対するイテレータを定義してみたよ。
type ToDoList{T<:String}
tasks::Vector{T}
finished::BitVector
function ToDoList(tasks::Vector{T})
finished = BitVector(length(tasks))
finished[1:end] = false
new(tasks, finished)
end
end
Base.start(list::ToDoList) = 1
Base.done(list::ToDoList, state) = findnext(!list.finished, state) == 0
function Base.next(list::ToDoList, state)
n = findnext(!list.finished, state)
list.tasks[n], n + 1
end
ちょっと待って、今のtype ToDoList{T<:String}って一体なに!?
型パラメータTに制約をつけてるんだよ。
ここではTがStringという抽象型(v0.4ではAbstractString)のサブクラスであることを強制してるんだよ。
インスタンス化するときは、
julia> ToDoList{ASCIIString}(["foo"])
ToDoList{ASCIIString}(ASCIIString["foo"],Bool[false])
というように呼び出すんだよ。
@show xとか@assert sum(x) == 10みたいなのは何? デコレータ?
@で始まるのはデコレータじゃなくてJuliaのマクロ呼出しだよ。これは実行前にJuliaのプログラムを書き換えることができるんだ。
デコレータは「関数を取って関数を返す関数」と考えられるけど、マクロは「式(expression)を取って式を返す関数」と考えられるよ。
モジュールってあるの?
Juliaもモジュール機能があるよ。
Pythonと違うのはPythonではファイルが自動的にモジュールになるのに対し、Juliaではmodule ... endで挟んだところがモジュールになるよ。
例えば、
module Foo1
function foo()
println("Foo1.foo")
end
end
module Foo2
function foo()
println("Foo2.foo")
end
end
という風にFoo1・Foo2の2つのモジュールを定義してfoos.jlファイルに保存して、
julia> include("foos.jl")
julia> Foo1.foo()
Foo1.foo
julia> Foo2.foo()
Foo2.foo
というようにしてそれぞれのfoo関数を使えるよ。
ちなみにPythonと同じようにimportがJuliaにもあるけど、暗黙的に名前を導入するusingの方がよく使われるよ。
そうそう例外は?
一番手軽なのはerrorという関数があるよ。
julia> error("!!!")
ERROR: !!!
in error at error.jl:21
例外の種類としては、PythonのValueError(不正な引数)に当たるDomainError、IndexError(存在しないキーへのアクセス)に当たるBoundsErrorなど色いろあるよ。
特定の例外を投げるにはthrow関数(errorでもOK)を使ってね。
julia> throw(DomainError()) ERROR: DomainError julia> error(DomainError()) ERROR: DomainError in error at error.jl:19
もちろん例外を捕まえるためにtry ... catch ... finally ... endというのもあるよ。
julia> try
error("panic!")
catch err
println("something bad happened")
println(err)
finally
println("and finally do something")
end
something bad happened
ErrorException("panic!")
and finally do something
文字列 / 正規表現
文字列の型は?
ASCIIStringとUTF8Stringの2つがあるよ。
Python2系のstrにあたるのがASCIIStringでunicodeにあたるのがUTF8Stringだよ。
両方をまとめるString(v0.4ではAbstractString)というより上位の型もあるよ。
文字列は不変?
基本的にそうだよ。でも以下のように文字列だってJuliaで定義されていて、内部にさわろうと思えば触れちゃうけどいじっちゃダメだよ!
immutable ASCIIString <: DirectIndexString
data::Array{UInt8,1}
end
immutable UTF8String <: AbstractString
data::Array{UInt8,1}
end
文字列の結合は?
*をつかうよ。
julia> "foo" * "bar" "foobar"
文字列の配列を結合するにはjoinを使うよ。
julia> join(["foo", "bar", "baz"], ',') "foo,bar,baz"
他にも色々比較や検索の関数があるよ!
.formatみたいな文字列のフォーマットは?
2つの方法があるよ。
- 変数の埋め込み
@sprintfマクロ- Formatting.jlでPythonの記法を使う。
変数の埋め込みはPythonで言うところの"... {} ...".format(x)に対応していて、文字幅などは指定せず単純に
変数を文字列に埋め込めるよ。
@sprintfマクロはC言語のようなフォーマットの指定が可能だよ。
さらに、Formatting.jlのformatでPythonの記法が使えるよ。
julia> n = 150;
julia> "n is $n"
"n is 150"
julia> @sprintf "n is %05d" n
"n is 00150"
julia> format("n is {}", n)
"n is 150"
julia> format("n is {:05d}", n)
"n is 00150"
複数行の文字列はどう書くの?
Pythonみたいに""" ... """が使えるよ!
julia> x = """ foo bar """ julia> print(x) foo bar
Pythonと違うのはJuliaの""" ... """では最初の改行文字が取り除かれるのに対し、Pythonでは除かれない点だよ。
つまり、
Julia:
""" foo bar """
と、
"""foo bar """
が同じ意味だよ。
正規表現はどう書くの?
例えば"090-1234-5678"みたいなのにマッチさせる正規表現ならr"\d{3}-\d{4}-\d{4}"と書けるよ。
ちなみに使える正規表現はPerl Compatible Regular Expression (PCRE)だよ。
正規表現の文字列の前のrは何? raw文字列?
実はこれもマクロだよ。
他にもv"1.2.3"みたいなバージョン文字列のマクロやb"DATA\xff\u2200"みたいなバイナリ列のマクロもあるよ。
マッチングはどうやるの?
ismatchを使ってね:
julia> ismatch(r"\d{3}", "123")
true
julia> ismatch(r"\d{3}", "12")
false
マッチした部分の抽出は?
()によるグルーピングが使えるよ。
m = match(r"(\d{3})-(\d{4})-(\d{4})", "090-1234-5678")
m.captures[1]
m.captures[2]
m.captures[3]
ファイル / IO
標準出力(sys.stdout)と標準エラー(sys.stderr)は?
STDOUTとSTDERRという変数が予め定義されているよ。
print(io, string)で改行なし、println(io, string)で改行付きで出力だよ。
標準入力から一行づつ読み込みたいんだけど?
readlineを使おう!
n = 1
for line in eachline(STDIN)
print("$n: $line")
n += 1
end
テキストファイルを一行づつ読み込みたいんだけど?
次のイディオムが使えるよ:
open("some.txt") do f
for line in eachline(f)
# do something
end
end
改行文字を取り除くには?
chomp関数を使おう!
julia> chomp("foobar\n")
"foobar"
書き込みは?
こんな感じだよ:
open("some.txt", "w") do f
println(f, "the first line")
println(f, "and more")
end
socketみたいなのは?
TCPソケットを通じてのデータのやり取りはlisten, accept, connectがあるよ。
システム
os.systemみたいに外部コマンドを実行したいんだけど。
バッククォート(\``)でコマンドを囲むとCmdオブジェクトができて、それをrun`関数で実行できるよ。
julia> `ls -la` `ls -la` julia> run(`ls -la`) total 1144 drwxr-xr-x+ 19 kenta staff 646 12 21 22:30 . drwxr-xr-x+ 30 kenta staff 1020 12 9 15:33 .. -rw-r-----@ 1 kenta staff 281892 12 5 01:02 6167c823c760479357b781d04c03b4a4.gif -rw-r--r--+ 1 kenta staff 412 12 21 22:03 bug.jl -rw-r--r--@ 1 kenta staff 176316 9 27 02:30 build_tree.png ...
subprocess.callみたいにコマンドの出力を受け取りたいなぁ。
ファイルを開くのと同じopen関数が実は使えるんだよ(ココ多重ディスパッチのいいところ!)。
コマンドの出力を一行づつ処理すのに便利だよ。
open(`command args`) do p
for line in eachline(p)
# do something
end
end
ファイルを開く時とそっくりだね!(再掲)
open("some.txt") do f
for line in eachline(f)
# do something
end
end
現在のディレクトリの取得は?
pwd関数を使おう!
ディレクトリの移動は?
cd関数を使おう!
次のようにdo ... endを使って一時的にディレクトリの移動も出来るよ!
julia> println(pwd())
/Users/kenta/snippets/JuliaAdvent
julia> cd("/tmp") do
println(pwd())
end
/private/tmp
julia> println(pwd())
/Users/kenta/snippets/JuliaAdvent
プロファイリング / ベンチマーク / テスト
timeitみたいに手軽に関数の実行時間を知りたいんだけど
@timeマクロは与えられた式を実行して、実行時間と割り当てられたメモリの量を教えてくれるよ。
julia> @time sum([1:1000000]) elapsed time: 0.005030125 seconds (8000168 bytes allocated) 500000500000
コードの何処に時間がかかってるか知りたいんだけど?
@profileマクロを使おう。
たとえばこんな関数とすると:
function func(n)
m = 2^n
s = BigInt(0)
for i in 1:m
s += sum(1:i)
end
s
end
結果を見るには以下のようにするよ:
julia> Profile.clear()
julia> @profile func(20)
192154133857304576
julia> Profile.print()
1 ./base.jl; finalizer; line: 147
1 ./bool.jl; !; line: 17
1 gmp.jl; +; line: 267
476 task.jl; anonymous; line: 96
476 REPL.jl; eval_user_input; line: 54
476 profile.jl; anonymous; line: 14
476 none; func; line: 5
389 gmp.jl; +; line: 267
300 ...lib/julia/sys.dylib; finalizer; (unknown line)
2 ./base.jl; finalizer; line: 0
91 ./base.jl; finalizer; line: 144
205 ./base.jl; finalizer; line: 147
72 gmp.jl; +; line: 268
4 gmp.jl; +; line: 269
3 range.jl; sum; line: 542
Juliaのプロファイラは実行途中にスタックのスナップショットを取って、何処に時間がかかってるかを割り出せるようになってるよ。左の数字が大きいところがコストのかかっている処理だよ。
gmp.jlのfinalizerでたくさんの時間がかかってる事がわかるね!
なんか数値計算で思ったよりパフォーマンスが上がらないんだけど...
数値計算などでC言語などに大きく水をあけられるケースの原因はいろいろ考えられるけど、よくあるのが変数の型が安定してないケースだよ。
次の配列xsの数値の総和を計算するケースを考えてみよう。
function mysum(xs)
s = 0
for x in xs
s += x
end
s
end
一見問題なさそうに思えるけど、実はxsの要素の型によってパフォーマンスがかなり変わってしまう問題があるコードだ。
数字の1を10,000,000個持った配列の和を求める下のベンチマークを見ると要素がIntの時に比べてFloat64のときにおよそ40倍も時間がかかっていることが分かるね。
mysum, Int
elapsed time: 0.010568369 seconds (16 bytes allocated)
mysum, Float64
elapsed time: 0.425763243 seconds (320000000 bytes allocated)
これの原因は変数sにあって、与えられた配列xsの要素がInt型の時はsの型は常にIntだけども、xsの要素がFloat64の時には
最初はsの型が= 0でIntに設定されるのに後でs += xとしたときにInt + Float64 → Float64に変わってしまうのが問題なんだ。
これをチェックすのにはcode_typed(f,types)関数(もしくはマクロ版の@code_typedマクロ)を使ってみよう。
例えばxsがVector{Int}のとき、sは::Int64で型付けされているけど、
julia> code_typed(mysum, (Vector{Int},))
1-element Array{Any,1}:
:($(Expr(:lambda, {:xs}, {{:s,symbol("#s119"),symbol("#s118"),:x,:_var1,:_var2,:_var0,:_var3},{{:xs,Array{Int64,1},0},{:s,Int64,2},{symbol("#s119"),Int64,2},{symbol("#s118"),(Int64,Int64),18},{:x,Int64,18},{:_var1,Int64,18},{:_var2,Int64,18},{:_var0,Int64,18},{:_var3,Int64,18}},{}}, :(begin # none, line 2:
s = 0 # line 3:
#s119 = 1
_var1 = (top(arraylen))(xs::Array{Int64,1})::Int64
unless (top(box))(Bool,(top(not_int))((top(slt_int))(_var1::Int64,#s119::Int64)::Bool))::Bool goto 1
2:
_var0 = (top(arrayref))(xs::Array{Int64,1},#s119::Int64)::Int64
_var3 = (top(box))(Int64,(top(add_int))(#s119::Int64,1))::Int64
x = _var0::Int64
#s119 = _var3::Int64 # line 4:
s = (top(box))(Int64,(top(add_int))(s::Int64,x::Int64))::Int64
3:
_var2 = (top(arraylen))(xs::Array{Int64,1})::Int64
unless (top(box))(Bool,(top(not_int))((top(box))(Bool,(top(not_int))((top(slt_int))(_var2::Int64,#s119::Int64)::Bool))::Bool))::Bool goto 2
1:
0: # line 6:
return s::Int64
end::Int64))))
xsがVector{Float64}のとき、sは::Union(Int64,Float64)で型付けされていて型が安定していないことが分かるね。
julia> code_typed(mysum, (Vector{Float64},))
1-element Array{Any,1}:
:($(Expr(:lambda, {:xs}, {{:s,symbol("#s119"),symbol("#s118"),:x,:_var1,:_var2,:_var0,:_var3},{{:xs,Array{Float64,1},0},{:s,Any,2},{symbol("#s119"),Int64,2},{symbol("#s118"),(Float64,Int64),18},{:x,Float64,18},{:_var1,Int64,18},{:_var2,Int64,18},{:_var0,Float64,18},{:_var3,Int64,18}},{}}, :(begin # none, line 2:
s = 0 # line 3:
#s119 = 1
_var1 = (top(arraylen))(xs::Array{Float64,1})::Int64
unless (top(box))(Bool,(top(not_int))((top(slt_int))(_var1::Int64,#s119::Int64)::Bool))::Bool goto 1
2:
_var0 = (top(arrayref))(xs::Array{Float64,1},#s119::Int64)::Float64
_var3 = (top(box))(Int64,(top(add_int))(#s119::Int64,1))::Int64
x = _var0::Float64
#s119 = _var3::Int64 # line 4:
s = s::Union(Int64,Float64) + x::Float64::Float64
3:
_var2 = (top(arraylen))(xs::Array{Float64,1})::Int64
unless (top(box))(Bool,(top(not_int))((top(box))(Bool,(top(not_int))((top(slt_int))(_var2::Int64,#s119::Int64)::Bool))::Bool))::Bool goto 2
1:
0: # line 6:
return s::Union(Int64,Float64)
end::Union(Int64,Float64)))))
これを防ぐにはsの型をxsの要素から直接得ればいいんだ。
function mysum_ok(xs)
s = zero(eltype(xs))
for x in xs
s += x
end
s
end
code_typedで確認してみると、Float64のときはsが::Float64で安定的に型付けされているのが分かるね。
julia> code_typed(mysum_ok, (Vector{Float64},))
1-element Array{Any,1}:
:($(Expr(:lambda, {:xs}, {{:s,symbol("#s119"),symbol("#s118"),:x,:_var1,:_var2,:_var0,:_var3},{{:xs,Array{Float64,1},0},{:s,Float64,2},{symbol("#s119"),Int64,2},{symbol("#s118"),(Float64,Int64),18},{:x,Float64,18},{:_var1,Int64,18},{:_var2,Int64,18},{:_var0,Float64,18},{:_var3,Int64,18}},{}}, :(begin # none, line 2:
s = (top(box))(Float64,(top(sitofp))(Float64,0))::Float64 # line 3:
#s119 = 1
_var1 = (top(arraylen))(xs::Array{Float64,1})::Int64
unless (top(box))(Bool,(top(not_int))((top(slt_int))(_var1::Int64,#s119::Int64)::Bool))::Bool goto 1
2:
_var0 = (top(arrayref))(xs::Array{Float64,1},#s119::Int64)::Float64
_var3 = (top(box))(Int64,(top(add_int))(#s119::Int64,1))::Int64
x = _var0::Float64
#s119 = _var3::Int64 # line 4:
s = (top(box))(Float64,(top(add_float))(s::Float64,x::Float64))::Float64
3:
_var2 = (top(arraylen))(xs::Array{Float64,1})::Int64
unless (top(box))(Bool,(top(not_int))((top(box))(Bool,(top(not_int))((top(slt_int))(_var2::Int64,#s119::Int64)::Bool))::Bool))::Bool goto 2
1:
0: # line 6:
return s::Float64
end::Float64))))
これでFloat64の時のパフォーマンスはぐっと良くなるよ。
mysum_ok, Int
elapsed time: 0.00833662 seconds (16 bytes allocated)
mysum_ok, Float64
elapsed time: 0.01434145 seconds (16 bytes allocated)
もちろん本当は色々工夫されている標準のsumを使ったほうがいいよ。
ベンチマークのコード全体は以下のとおりだよ。
function mysum(xs)
s = 0
for x in xs
s += x
end
s
end
function mysum_ok(xs)
s = zero(eltype(xs))
for x in xs
s += x
end
s
end
function bench(func::Function, eltype::DataType)
# pre-compile
func([one(eltype)])
xs = ones(eltype, 10_000_000)
gc_disable()
@time func(xs)
gc_enable()
gc()
end
let
println("mysum, Int")
bench(mysum, Int)
println("mysum, Float64")
bench(mysum, Float64)
println("mysum_ok, Int")
bench(mysum_ok, Int)
println("mysum_ok, Float64")
bench(mysum_ok, Float64)
println("Base.sum, Int")
bench(Base.sum, Int)
println("Base.sum, Float64")
bench(Base.sum, Float64)
end
結果はこんなかんじ。
mysum, Int
elapsed time: 0.010568369 seconds (16 bytes allocated)
mysum, Float64
elapsed time: 0.425763243 seconds (320000000 bytes allocated)
mysum_ok, Int
elapsed time: 0.00833662 seconds (16 bytes allocated)
mysum_ok, Float64
elapsed time: 0.01434145 seconds (16 bytes allocated)
Base.sum, Int
elapsed time: 0.006605981 seconds (16 bytes allocated)
Base.sum, Float64
elapsed time: 0.006086415 seconds (16 bytes allocated)
そうそう単体テストは?
標準ライブラリにあるBase.Testを使うよ。
@testマクロがtrueになるような式を渡してね。
julia> using Base.Test julia> @test 1 == 1 julia> @test 1 == 2 ERROR: test failed: 1 == 2 in error at error.jl:21 in default_handler at test.jl:19 in do_test at test.jl:39
他に例外を投げることを確認する@test_throwsと、浮動小数点数がほぼ同じ値であることを確認する@test_approx_eqもあるよ。
ライブラリ
requestsみたいなのは?
Requests.jlが近いかな!
YAMLやJSONやXMLは?
pandasみたいなデータフレームは?
DataFrames.jlがあるよ!
プロットしたいんだけど?
一番使われてるのはGadfly.jlかな。 チョット動作が遅いけど簡単によくあるプロットができるよ。
Pythonistaの人にはMatplotlibをJuliaでラップしたPyPlot.jlがあるよ。
IPython Notebookは?
IJulia.jlがあるよ!
最近はJupyterも注目だね! もちろんJupyterのJuはJuliaのJuだよ!
コマンドライン引数のパースするには?
オススメはPythonのdocoptから移植されたDocOpt.jlだよ!。 詳しくはPythonのコマンドライン引数処理の決定版 docopt (あとJuliaに移植したよ)を見てね。 他にもArgParse.jlというのもあるよ。
Flake8みたいな静的なコードのチェッカーが欲しいんだけどなぁ
JuliaにはPEP8に相当するものは今のところないからスタイルに関してはかなり自由だけど、 List.jlでよくある間違いを事前に発見できるよ。
統計とか機械学習とかのライブラリが知りたい!
思いつく限り!
- GLM.jl - 一般化線形モデルのライブラリ
- GLMNet.jl - LassoとElastic Netのライブラリ
- HypothesisTests.jl - 統計的仮説検定のライブラリ
- PValueAdjust.jl - p値の補正ライブラリ
- StatsBase.jl - 統計関係の便利ライブラリ
- Distances.jl - 様々な距離を測るライブラリ
- KernelDensity.jl - カーネル密度推定のライブラリ
- SVM.jl - SVMのライブラリ(純Julia製)
- LIBSVM.jl - SVMのライブラリ(libsvmのバインディング)
- DecisionTree.jl - 決定木とRandom Forestのライブラリ(ID3)
- RandomForests.jl - Random Forestのライブラリ(CART 俺製)
- Lora.jl - MCMCのライブラリ(元MCMC.jl)
- Mamba.jl - MCMCのライブラリ
- FANN.jl - Neural Networkのライブラリ
- Mocha.jl - Deep Learningのライブラリ
- MLBase.jl - 機械学習関係の便利ライブラリ
- NMF.jl - non-negative matrix factorizationのライブラリ
他にもJuliaStatsに色いろあるよ!
もっと資料や読み物を教えて!
言語をよく知りたいならJuliaの公式マニュアルを読もう!質も量も素晴らしいマニュアルだよ!
- Julia Documentation
- 公式マニュアル
- The Standard Library
- Juliaの標準ライブラリ(必須レファレンス)
他にも、Worth Readingな記事を挙げていくよ!
- Out in the Open: Man Creates One Programming Language to Rule Them All
- WIREDの記事。なぜJuliaなんて言語を作ったのかという話
- Tricks in Julia
- Juliaの小技集
- The Relationship between Vectorized and Devectorized Code
- JuliaとRのベクトル化の考え方の違い
- Fast Numeric Computation in Julia
- Juliaで高速な数値計算を行うときのコツ
- Vectorization in Julia
- NumericExtensions.jl / NumericFuns.jl
- 夜道さんの記事。パッケージを使った数値計算の高速化手法
- Performance Tips
- Juliaマニュアルのパフォーマンスを上げるTips
Unicodeプログラミングのすゝめ
Julia Advent Calendar 2014 4日目の記事です。
以前、工学部の友人から「変数mとuの積をmuと書いたと思ったら、パラメータμをmuと書いてたりするFortranのコードがあって混乱する」という話を聞きました。
最近の言語はUnicodeを使える物も多いですが(Unicode variable names)、そんなに積極的に使われているわけでもありません。
Juliaは根っからのUnicode好きです。Unicode(UTF8)文字列を最初からサポートしていることはもちろん、 変数名や関数名などに自由にUnicode文字を使えます。
Juliaの対話セッションを立ち上げて、\pi<Tab>と入力してみましょう。
~/v/julia (master|…) $ julia -q
julia> π
π = 3.1415926535897...
julia>
\piがギリシャ文字のπに変化しましたね。
これはJuliaの定数で、piもしくはπに束縛されています。
他のUnicode文字についても、LaTeXの記法を用いてREPLに入力できます。
\alpha<Tab>, \beta<Tab>, \psi<Tab>などいろいろ試してみましょう。
当然、漢字だって使えます。
julia> 円周率 = π
π = 3.1415926535897...
julia> 円周率
π = 3.1415926535897...
julia> 半径 = 4.0
4.0
julia> 半径^2 * 円周率
50.26548245743669
エディタで入力する
REPLで使えてもあんまり嬉しくないかもしれません。かといってαを入力するのに エディタで「あるふぁ」と打って変換するのも面倒です。 実はVimなら簡単にUnicode文字を使ってプログラミングをできます。 そのためには、julia-vimを導入する必要があります。
julia-vimではJuliaのREPLと同じように\alpha<Tab>と入力するとαに変換されるようになっています。
つまり、
a + \alpha
の次にTabキーを押すと
1 + α
と変換されます。 この設定は、Juliaファイルについてはデフォルトで有効です。
EmacsについてもJuliaのcontrib/julia-mode.elにLaTeX => Unicodeの変換表がありますので同様のことが可能だと思います(Emacs使いじゃないので分かりません。ゴメンナサイ)。

実際のコード
この機能を使って、擬似コードをそっくりそのままJuliaのコードに翻訳してみました。
次の擬似コードは (Hoffman, 2014) のコードです。 ここでは何をやっているコードかは気にする必要はありません。

これを見た上で、下のJuliaのコードを見てみましょう。 これは、実際に動くコードです。
function build_tree(L::Function, ∇L::Function, θ::Vector{Float64}, r::Vector{Float64}, u::Float64, v::Int, j::Int, ϵ::Float64)
if j == 0
θ′, r′ = leapfrog(∇L, θ, r, v * ϵ)
C′ = u ≤ exp(L(θ′) - r′ ⋅ r′ / 2) ? Set([(θ′, r′)]) : Set([])
s′ = int(L(θ′) - r′ ⋅ r′ / 2 > log(u) - Δmax)
return θ′, r′, θ′, r′, C′, s′
else
θ⁻, r⁻, θ⁺, r⁺, C′, s′ = build_tree(L, ∇L, θ, r, u, v, j - 1, ϵ)
if v == -1
θ⁻, r⁻, _, _, C″, s″ = build_tree(L, ∇L, θ⁻, r⁻, u, v, j - 1, ϵ)
else
_, _, θ⁺, r⁺, C″, s″ = build_tree(L, ∇L, θ⁺, r⁺, u, v, j - 1, ϵ)
end
s′ = s′ * s″ * ((θ⁺ - θ⁻) ⋅ r⁻ ≥ 0) * ((θ⁺ - θ⁻) ⋅ r⁺ ≥ 0)
C′ = C′ ∪ C″
return θ⁻, r⁻, θ⁺, r⁺, C′, s′
end
end
変数の対応関係がそっくりそのまま分かるほど似ていませんか?
不等号(≥)や集合の和(∪)もJuliaの関数として既に定義されています。
ちなみに、⁺と″はそれぞれ\^+<Tab>と\pprime<Tab>で入力できます。
コード全体はnuts.jlから入手できます。
おまけ
絵文字も使えます。絵文字を使うにはmasterブランチのJuliaが必要です。

次は@kimrinさんです。
X分で学ぶJulia
- 2016/11/20 追記: この記事は内容が一部古くなっています。最新版はこちらを参照して下さい
Julia Advent Calendar 2014 1日目の記事です。
まだまだJuliaは一般に知られていない言語ということもありまして、Juliaの基本的な機能を最短で学ぶ記事を初日に書いた次第です。 X<30くらいだと思います。
バージョンはJuliaの最新リリース版であるv0.3系を基にしていますが、特に異なる点は次期バージョンであるv0.4に関しても触れています。
Juliaの公式サイトは The Julia Language で 、Juliaのバイナリは Julia Downloads から入手できます。
文法
百聞は一見にしかず。まずはJuliaのコードをざっと見てみましょう。
function mandel(z) c = z maxiter = 80 for n = 1:maxiter if abs(z) > 2 return n-1 end z = z^2 + c end return maxiter end function randmatstat(t) n = 5 v = zeros(t) w = zeros(t) for i = 1:t a = randn(n,n) b = randn(n,n) c = randn(n,n) d = randn(n,n) P = [a b c d] Q = [a b; c d] v[i] = trace((P.'*P)^4) w[i] = trace((Q.'*Q)^4) end std(v)/mean(v), std(w)/mean(w) end
From: http://julialang.org/
どうでしょう?PythonやRubyをやったことがる人なら初見でも大体の意味が分かるのではないでしょうか?
関数定義・分岐・反復などの構文はそれぞれfunction ... end, if ... end, for ... end, while ... endのようにキーワードで始まりendで終わります。
ちょうどRubyと同じような感じです。
インデントはPythonのように必要ではありませんが、4スペースでひとつのインデントを表すのが慣習です。
また、変数の宣言や型の指定は通常必要ありません。
こうしたコードはJuliaのLLVMベースのJITコンパイラによりコンパイルされ、C言語などで書いたコードとそれほど変わらない速度で実行できます。
変数
変数は特別に宣言せずとも初期化と同時に使用できます。
functionやforなどほとんどのブロックは変数のスコープを新たに作ります。これはPythonなどと動作が異なりますので注意が必要です。例外的にスコープを作らないのはif ... endとbegin ... endです。
for i in 1:10 x = i end println(x) # ERROR: x not defined
if true x = 10 end println(x) # OUTPUT: 10
トップレベルで定義された変数はグローバル変数になります。
グローバル変数はコンパイラの最適化を難しくするため、constをつけて定義すべきです。
数値型
Juliaの値は型を持ちます。Juliaでは動的に型がつき、様々な機能と密接に関わってきます。
整数型はsigned, unsignedと8bit, 16bit, 32bit, 64bit, 128bitの組み合わせとBool型とBigInt型で合計12種類あり、
それぞれsigned 64bitはInt64やunsigned 32bitはUint32など一貫性のある型名がつけられています(v0.4でUintはUIntに改名)。
浮動小数点の型も16bit, 32bit, 64bitとBigFloat型で合計4種類があります。
BigInt型とBigFloat型はそれぞれ任意精度の整数と浮動小数点数です。
他には複素数のComplex{T}型があり、Tという 型パラメータ(type parameter) で実部と虚部の数値の型を指定します。ちょうどHaskellの型変数(type variable)のようなものです。
科学計算のために作られているJuliaは、このように豊富な数値の方を持つ点が魅力のひとつです。
リテラル
大抵、何らかの値を作るリテラルは他の言語と同じです。
- 数値
- 文字(列)
- 文字
Char型:'a','樹' - 文字列
ASCIIString型:"deadbeef","""Triple Quote String"""
- 文字
- その他
- 真偽値
Bool型:true,false - シングルトン
Nothing型:nothing(v0.4ではVoid型)
- 真偽値
IntはInt32またはInt64のエイリアスです。
Juliaの対話実行環境(REPL)で確認してみましょう。
型はtypeof関数で確認できます。
~/s/JuliaAdvent $ julia
_
_ _ _(_)_ | A fresh approach to technical computing
(_) | (_) (_) | Documentation: http://docs.julialang.org
_ _ _| |_ __ _ | Type "help()" for help.
| | | | | | |/ _` | |
| | |_| | | | (_| | | Version 0.3.0 (2014-08-20 20:43 UTC)
_/ |\__'_|_|_|\__'_| |
|__/ | x86_64-apple-darwin13.3.0
julia> 42
42
julia> typeof(42)
Int64
julia> typeof(1.0)
Float64
julia> '漢'
'漢'
julia> typeof('漢')
Char
julia> typeof("deadbeef")
ASCIIString (constructor with 2 methods)
julia> typeof(true)
Bool
julia> typeof(nothing)
Nothing (constructor with 1 method)
ベクトルは[]で記述できます。
Juliaではインデックスは1始まりなので注意が必要です。
julia> [1,2,3]
3-element Array{Int64,1}:
1
2
3
julia> x = [1,2,3]
3-element Array{Int64,1}:
1
2
3
julia> x[1]
1
以降対話セッションは>で表現します。
型
Juliaの値はひとつの 具体的な 型を持ちます。一部例外を除いて、型が自動的に別の型にキャストされることはありません
(一部例外とは、1 + 1.5などの数値計算とコンストラクタです。 http://julia.readthedocs.org/en/latest/manual/conversion-and-promotion/)。
ここで、 具体的(concrete)な とわざわざ述べたのは、Juliaにはこれと対極をなす 抽象的(abstract)な 型があるためです。 適切な訳語がわからないため、ここでは原文通り具体的な型を「具体型」、抽象的な型を「抽象型」と表記します。
最も大きな違いは具体型はインスタンス化可能な一方で抽象型はインスタンス化ができない点です。
即ち、任意のxに対して、typeof(x)の結果は必ず具体型になります。
抽象型は具体型や他の抽象型のsupertypeとして機能し、型間のsubtype/supertypeの関係性は木構造のグラフをとります。
さらに、具体型は他の型のsupertypeにはなれませんので、必然的にグラフの葉が具体型に、内部ノードが抽象型となります。
このグラフの根にあるのがAnyという抽象型です。
Juliaでユーザーが型を定義するとデフォルトでこのAny型のsubtypeになります。
(厳密には、Noneという具体型を含む全ての型のsubtypeになっている抽象型があります。)
具体例で確認しましょう。Int64とInt32は共に具体型で、Integerという抽象型のsubtypeになっています。
具体型はisleaftype、subtype/supertypeの関係は<:という関数で確認できます。
> isleaftype(Int64) true > isleaftype(Int32) true > isleaftype(Integer) false > Int64 <: Integer true > Int32 <: Integer true
自分で型を作るのも簡単です。
以下のようにtypeまたはimmutableに続けて型名を書き、フィールドを定義します。
type Person name::UTF8String age::Int end immutable Point x::Float64 y::Float64 end
デフォルトコンストラクタがありますので、即座にインスタンス化できます。
インスタンスのフィールドへは.でアクセスできます。
person = Person("佐藤建太", 24) point = Point(1.0, 2.0) println("Hello, my name is $(person.name) and $(person.age) years old.")
関数/メソッド
Juliaの関数定義には二種類の書き方があります。
手続き型言語っぽい通常の関数定義と、関数型言語っぽい=を用いた記法です。
# 手続き型風 (複数行のときに好まれる) function add_one(x) x + 1 end # 関数型風 (一行で書けるときに好まれる) add_one(x) = x + 1
返り値を表すreturnはPerlやRubyのように省略可能です。
関数の引数は基本的に参照渡しのようになりますが、引数値の変数への束縛を変更できないため、immutableな型(例えばIntやASCIIString)の値は関数内で変更できません。
逆にmutableな型(例えばArrayなどの配列)の値は関数内で変更することができます。
以下の例では標準のsort!関数で破壊的に配列の中身をソートしています。
Juliaでは破壊的な関数の名前に!をつけるのが慣習です。
> x = [4, 1, 2, 3]
4-element Array{Int64,1}:
4
1
2
3
> sort!(x)
4-element Array{Int64,1}:
1
2
3
4
> x
4-element Array{Int64,1}:
1
2
3
4
Juliaの他のスクリプト言語と違う大きな特徴のひとつが関数の 多重ディスパッチ(multiple dispatch) です。 これは、引数の型の組み合わせによって呼び出されるメソッドの実体が異なるという振る舞いを実現できます。
簡単な例で動作を確認しましょう。次の関数fooは4つの異なる実装を持ちます。
function foo(x::Int) println("foo Int: $x") end function foo(x::Int, y::Int) println("foo Int Int: $x $y") end function foo(x::Float64, y::Float64) println("foo Float64 Float64: $x $y") end function foo(x::Int, y::Float64) println("foo Int Float64: $x $y") end
見ての通り、<仮引数>::<型>の形で引数の型を指定できます。
これらの型の異なるメソッドは、呼び出し側の引数の型にマッチするものが実行されます。
もちろん、ユーザが定義した型に対しても同様に振る舞います。
以下のように型にマッチするものがない場合、その関数呼び出しはエラーになります。
> foo(1) foo Int: 1 > foo(1, 2) foo Int Int: 1 2 > foo(1.0, 2.0) foo Float64 Float64: 1.0 2.0 > foo(1, 2.0) foo Int Float64: 1 2.0 > foo(1.0, 2) ERROR: `foo` has no method matching foo(::Float64, ::Int64)
このように、Juliaではメソッドは関数に従属します。これは、メソッドがクラスに従属するクラスベースのプログラミング言語とは大きく異なります。
キーワード引数やオプショナル引数、可変長引数なども使えます。
=の後に値を書くとオプショナルな引数として認識され、引数の区切りを,の代わりに;を使うとそれ以降の引数がキーワード引数として扱われます。
args...とすると、仮引数argsは定義内ではタプルとなります。
# オプショナル引数 head(seq, n::Int=10) = seq[1:n] # キーワード引数 function optimize(func; iter=100, rate=0.1, alg=GradientDescent) # ... end # 可変長引数 sumof(args...) = sum(args)
- http://julia.readthedocs.org/en/latest/manual/functions/
- http://julia.readthedocs.org/en/latest/manual/methods/
構文糖衣
ここではJuliaで見られる特殊な構文をざっと見て行きます。
係数
変数の前に数値をつけると、暗黙的に積だと解釈されます。
これは多項式の記述や12pxなど単位の記述に便利です。
> x = 2.1 2.1 > 2x 4.2 > 4x^2 + 3x + 2 25.94
範囲
配列から一部を取り出したり、ある範囲で反復すときなどに便利なのが範囲型です。
基本的な文法はstart:endもしくはstart:step:endのようにコロンで区切って記述します。
範囲自体もオブジェクトですので、変数に収めたり関数に渡したりもできます。
> 1:4
1:4
> for i in 1:4
println(i)
end
1
2
3
4
> 1:2:10
1:2:10
> for i in 1:2:10
println(i)
end
1
3
5
7
9
配列から一部を取り出すのにも範囲は使用されます。
終端はendで指定できます。
> x = [1,2,3,4,5]
5-element Array{Int64,1}:
1
2
3
4
5
> x[1:3]
3-element Array{Int64,1}:
1
2
3
> x[4:end]
2-element Array{Int64,1}:
4
5
> x[2:end-2]
2-element Array{Int64,1}:
2
3
内包表記
配列や辞書はPythonのような内包表記で記述できます。
> [x for x in 1:4]
4-element Array{Int64,1}:
1
2
3
4
> [c => i for (c, i) in zip('a':'f', 1:6)]
Dict{Char,Int64} with 6 entries:
'd' => 4
'f' => 6
'b' => 2
'e' => 5
'c' => 3
'a' => 1
ベクトル/行列
Juliaにおいてベクトルとは、一次元配列のことです。 ベクトルは以下のように記述します。
> [1, 2, 3]
3-element Array{Int64,1}:
1
2
3
,を抜かすと、2次元の配列(行列)として解釈されます。
> [1 2 3]
1x3 Array{Int64,2}:
1 2 3
複数行の行列の記述は、以下のように;で書けます。
> [1 2 3; 4 5 6]
2x3 Array{Int64,2}:
1 2 3
4 5 6
式の後に'をつけると行列の転置になります。
> [1 2 3; 4 5 6]'
3x2 Array{Int64,2}:
1 4
2 5
3 6
無名関数
->を使うことで、無名関数を記述できます。
> x -> 2x
(anonymous function)
> map(x -> 2x, [1,2,3])
3-element Array{Int64,1}:
2
4
6
ブロック引数
第一引数に関数をとる関数は、位置を逆転させて代わりにdo ... endブロックを取ることができます。
即ち、以下の2つが同じ意味になります。
# 関数引数が先 map(x -> 2x, [1,2,3]) # 関数引数の代わりにブロックをとる map([1,2,3]) do x 2x end
これは、関数の中身が大きい場合に特に便利です。
さらに、ファイルを開いて自動的に閉じる処理の記述にも使われています。 以下のコードはファイルを開いて一行づつ処理をするパターンです。
open("somefile.txt") do f for line in eachline(f) # ... end end
非標準文字列
Juliaでは文字列の前に識別子をおくと、通常の文字列ではなくマクロとして解釈されます。 これを利用して、正規表現を記述できます。
> r"\w-\d \w+"
r"\w-\d \w+"
> match(r"\w-\d \w+", "B-2 Spirit")
RegexMatch("B-2 Spirit")
他にはバージョン文字列の記述にも利用されています。
> v"1.2.3" v"1.2.3"
外部コマンド
バッククォートで囲うことでコマンドを記述できます。
作られたコマンドはrun関数で実行できます。
> `ls -la` `ls -la` > typeof(`ls -la`) Cmd > run(`ls -la`) total 40 drwxr-xr-x+ 4 kenta staff 136 11 30 20:57 . drwxr-xr-x+ 26 kenta staff 884 11 29 17:17 .. -rw-r--r--+ 1 kenta staff 12692 11 30 20:57 learnjulia.md -rw-r--r--+ 1 kenta staff 234 11 29 18:10 sample.jl
便利なマクロ
@マークで始まる式は、コンパイル時に別の式に展開されます。この機能を マクロ といいます。
別の言い方をすれば、通常の関数が実行時に値を取って値を返すのに対し、マクロとはコンパイル時に式を取って式を返す関数と言えます。
以下の例はアサーションに失敗すると例外を投げる@assertマクロと、変数の状態をプリントする@showマクロです。
これら2つはデバッグなどに大変役立ちます。
> x = 100 100 > @assert x < 10 ERROR: assertion failed: x < 10 in error at error.jl:21 > @show x x = 100 100
@printfマクロは書式を指定したプリントのためのマクロです。
> @printf "line %3d: %s\n" 42 "foo" line 42: foo
ベンチマークなどに使えるのが実行時間とアロケートされたメモリを測る@timeマクロです。
最初の呼び出し時にはJITコンパイル分のオーバーヘッドがかかりますので注意が必要です。
> fib(n) = if n < 2 1 else fib(n-1) + fib(n-2) end fib (generic function with 1 method) > @time fib(10) elapsed time: 0.001739938 seconds (47552 bytes allocated) 89 > @time fib(20) elapsed time: 9.9135e-5 seconds (96 bytes allocated) 10946 > @time fib(40) elapsed time: 1.160873359 seconds (96 bytes allocated) 165580141
@code_llvmと@code_nativeは関数呼び出しで実行されるLLVMとネイティブコードをプリントします。
パフォーマンスが上がらない時などに原因を探るのに便利です。
> @code_llvm fib(10)
define i64 @"julia_fib;42387"(i64) {
top:
%1 = icmp sgt i64 %0, 1, !dbg !1280
br i1 %1, label %L, label %if, !dbg !1280
if: ; preds = %top
ret i64 1, !dbg !1282
L: ; preds = %top
%2 = add i64 %0, -1, !dbg !1282
%3 = call i64 @"julia_fib;42374"(i64 %2), !dbg !1282
%4 = add i64 %0, -2, !dbg !1282
%5 = call i64 @"julia_fib;42374"(i64 %4), !dbg !1282
%6 = add i64 %5, %3, !dbg !1282
ret i64 %6, !dbg !1282
}
> @code_native fib(10)
.section __TEXT,__text,regular,pure_instructions
Filename: none
Source line: 1
push RBP
mov RBP, RSP
push R15
push R14
push RBX
push RAX
mov RBX, RDI
cmp RBX, 1
jle L67
Source line: 1
lea RDI, QWORD PTR [RBX - 1]
movabs R15, 4534292768
call R15
mov R14, RAX
add RBX, -2
mov RDI, RBX
call R15
add RAX, R14
L56: add RSP, 8
pop RBX
pop R14
pop R15
pop RBP
ret
L67: mov EAX, 1
jmpq L56
マクロの書き方はちょっと入門の範囲を超えるので省略します。
パッケージ
JuliaのパッケージはGitレポジトリです。Julia本体もパッケージもGitHubを中心に回っています。 現在、Mercurialなど他のバージョン管理システムには対応していません。 しかし、パッケージ開発者を除くユーザとしてはGit自体を学ぶ必要はありません。 パッケージのインストールはJuliaの対話セッションから行うことができます。
> Pkg.add("DocOpt")
INFO: Installing DocOpt v0.0.2
INFO: Package database updated
ほか、レポジトリのメタデータのアップデートはPkg.update()で可能です。
公式に利用可能なパッケージはhttp://pkg.julialang.org/から一覧できます。
それ以外にもPkg.cloneを使うことで、公式レポジトリにはないがGitHubなどのGitレポジトリから直接インストールすることもできます。
その他
この記事では深く扱わなかった重要な部分については、Juliaのマニュアルへのリンクを張っておきます。 Juliaのマニュアルはとても読みやすく、それだけでプログラミング言語の勉強になるほど質の良いものです。
- 例外 http://julia.readthedocs.org/en/latest/manual/control-flow/#exception-handling
- モジュール http://julia.readthedocs.org/en/latest/manual/modules/
- 並列計算 http://julia.readthedocs.org/en/latest/manual/parallel-computing/
- C/Fortranの呼び出し http://julia.readthedocs.org/en/latest/manual/calling-c-and-fortran-code/
- コンストラクタ http://julia.readthedocs.org/en/latest/manual/constructors/
- 標準ライブラリ http://julia.readthedocs.org/en/latest/stdlib/base/
Consensus CDSの領域をGRangesオブジェクトにする
Bioconductor - TxDb.Hsapiens.UCSC.hg19.knownGeneは便利なのですが、ある遺伝子に対応するtranscriptが多すぎてどうしたものかと困ってました。
で、UCSCのゲノムブラウザで見るとConsensus CDS(CCDS)のアノテーションもあるのですが、このBioconductorのパッケージからそれを取得する方法が分かりませんでした。
正確にはmakeTranscriptDbFromUCSC(genome="hg19", tablename="ccdsGene")などとしてCCDSの領域は取得はできるんですが、他のアノテーション(Gene IDなど)が一切消えるので全く使いものにならない感じです。
仕方がないのでCCDS ProjectのFTPサーバから元データを引っ張ってきてそれをパースしてアノテーションのあるCCDSのデータを作ったのでちょろっと共有しておきます。
まずはCCDS ProjectのFTPサーバからCCDSの領域とアノテーションを収めたファイルを取得します (ftp://ftp.ncbi.nlm.nih.gov/pub/CCDS/)。 reference genomeのビルドによっていくつかありますので、自分の目的に合ったものを取得しましょう。 私はftp://ftp.ncbi.nlm.nih.gov/pub/CCDS/archive/Hs37.3/CCDS.current.txtを取りました。
次にこのデータをRがパースしやすいようにPerlで整形します。元データはこんな感じのでデータになってます。
CCDS.current.txt:
#chromosome nc_accession gene gene_id ccds_id ccds_status cds_strand cds_from cds_to cds_locations match_type 1 NC_000001.8 LINC00115 79854 CCDS1.1 Withdrawn - 801942 802433 [801942-802433] Identical 1 NC_000001.10 SAMD11 148398 CCDS2.2 Public + 861321 879532 [861321-861392, 865534-865715, 866418-866468, 871151-871275, 874419-874508, 874654-874839, 876523-876685, 877515-877630, 877789-877867, 877938-878437, 878632-878756, 879077-879187, 879287-879532] Identical 1 NC_000001.10 NOC2L 26155 CCDS3.1 Public - 880073 894619 [880073-880179, 880436-880525, 880897-881032, 881552-881665, 881781-881924, 883510-883611, 883869-883982, 886506-886617, 887379-887518, 887791-887979, 888554-888667, 889161-889271, 889383-889461, 891302-891392, 891474-891594, 892273-892404, 892478-892652, 894308-894460, 894594-894619] Identical 1 NC_000001.10 PLEKHN1 84069 CCDS4.1 Public + 901911 909954 [901911-901993, 902083-902182, 905656-905802, 905900-905980, 906065-906137, 906258-906385, 906492-906587, 906703-906783, 907454-907529, 907667-907803, 908240-908389, 908565-908705, 908879-909019, 909212-909430, 909695-909743, 909821-909954] Identical 1 NC_000001.10 HES4 57801 CCDS5.1 Public - 934438 935352 [934438-934811, 934905-934992, 935071-935166, 935245-935352] Identical 1 NC_000001.10 ISG15 9636 CCDS6.1 Public + 948953 949857 [948953-948955, 949363-949857] Identical 1 NC_000001.10 C1orf159 54991 CCDS7.2 Public - 1018272 1026922 [1018272-1018366, 1019732-1019762, 1019860-1019885, 1021257-1021391, 1022518-1022583, 1022881-1022976, 1025732-1025807, 1026851-1026922] Identical 1 NC_000001.10 TTLL10 254173 CCDS8.1 Public + 1115433 1120521 [1115433-1115719, 1115862-1115980, 1116110-1116239, 1117120-1117194, 1117740-1117825, 1118255-1118426, 1119299-1119470, 1120348-1120521] Identical 1 NC_000001.10 TNFRSF18 8784 CCDS9.1 Public - 1138970 1141950 [1138970-1139339, 1139778-1139865, 1140749-1140871, 1141764-1141950] Identical
CDS領域の範囲が一行に収められてます。 RマスターならRでもサクッといけるんでしょうが、私は以下のPerlスクリプトで事前にTSVファイルに変換しました。 (追記: CCDSの入力ファイルが0-based coordinateだったので1-basedに修正)
parse_ccds.pl:
#!/usr/bin/env perl use v5.10; use strict; use warnings; say "chromosome\tnc_accession\tgene\tgene_id\tccds_id\tccds_status\tcds_strand\tcds_from\tcds_to\tmatch_type\tstart\tstop"; while (<>) { next if /^#/; chomp; my ($chromosome, $nc_accession, $gene, $gene_id, $ccds_id, $ccds_status, $cds_strand, $cds_from, $cds_to, $cds_locations, $match_type) = split /\t/; my @cds_ranges = map { my ($start, $stop) = split /-/; {start => $start+1, stop => $stop+1} } (split /,\s/, (substr $cds_locations, 1, -1)); foreach (@cds_ranges) { say "$chromosome\t$nc_accession\t$gene\t$gene_id\t$ccds_id\t$ccds_status\t$cds_strand\t$cds_from\t$cds_to\t$match_type\t$_->{start}\t$_->{stop}"; } }
そして、tsvファイルを吐きます。
cat CCDS.current.txt | perl parse_ccds.pl > CCDS.current.tsv
あとはRで読み込むだけです。幸い、makeGRangesFromDataFrameを使うことで、読み込んだデータフレームを簡単にGRangesオブジェクトに変換できます。
> library(GenomicRanges)
> ccds = read.csv("CCDS.current.tsv", sep="\t")
> ccds = makeGRangesFromDataFrame(ccds, strand.field="cds_strand", keep.extra.columns=T)
> ccds
GRanges object with 287116 ranges and 8 metadata columns:
seqnames ranges strand | nc_accession gene gene_id ccds_id ccds_status cds_from cds_to
<Rle> <IRanges> <Rle> | <factor> <factor> <integer> <factor> <factor> <integer> <integer>
[1] 1 [801942, 802433] - | NC_000001.8 LINC00115 79854 CCDS1.1 Withdrawn 801942 802433
[2] 1 [861321, 861392] + | NC_000001.10 SAMD11 148398 CCDS2.2 Public 861321 879532
[3] 1 [865534, 865715] + | NC_000001.10 SAMD11 148398 CCDS2.2 Public 861321 879532
[4] 1 [866418, 866468] + | NC_000001.10 SAMD11 148398 CCDS2.2 Public 861321 879532
[5] 1 [871151, 871275] + | NC_000001.10 SAMD11 148398 CCDS2.2 Public 861321 879532
... ... ... ... ... ... ... ... ... ... ... ...
[287112] Y [16168463, 16168738] + | NC_000024.9 VCY1B 353513 CCDS56618.1 Public 16168169 16168738
[287113] Y [16835028, 16835148] + | NC_000024.9 NLGN4Y 22829 CCDS56619.1 Public 16835028 16953141
[287114] Y [16936067, 16936252] + | NC_000024.9 NLGN4Y 22829 CCDS56619.1 Public 16835028 16953141
[287115] Y [16941609, 16942398] + | NC_000024.9 NLGN4Y 22829 CCDS56619.1 Public 16835028 16953141
[287116] Y [16952292, 16953141] + | NC_000024.9 NLGN4Y 22829 CCDS56619.1 Public 16835028 16953141
match_type
<factor>
[1] Identical
[2] Identical
[3] Identical
[4] Identical
[5] Identical
... ...
[287112] Identical
[287113] Identical
[287114] Identical
[287115] Identical
[287116] Identical
-------
seqinfo: 24 sequences from an unspecified genome; no seqlengths
遺伝子毎のCDS領域を得たければ、Gene IDのアノテーションがccdsにありますのでsplitでGRangesListオブジェクトにできます。
> ccdsbygene = split(ccds.public, ccds.public$gene_id)
> ccdsbygene
GRangesList object of length 18383:
$1
GRanges object with 8 ranges and 8 metadata columns:
seqnames ranges strand | nc_accession gene gene_id ccds_id ccds_status cds_from cds_to
<Rle> <IRanges> <Rle> | <factor> <factor> <integer> <factor> <factor> <integer> <integer>
[1] 19 [58858387, 58858394] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
[2] 19 [58858718, 58859005] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
[3] 19 [58861735, 58862016] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
[4] 19 [58862756, 58863052] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
[5] 19 [58863648, 58863920] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
[6] 19 [58864293, 58864562] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
[7] 19 [58864657, 58864692] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
[8] 19 [58864769, 58864802] - | NC_000019.9 A1BG 1 CCDS12976.1 Public 58858387 58864802
match_type
<factor>
[1] Identical
[2] Identical
[3] Identical
[4] Identical
[5] Identical
[6] Identical
[7] Identical
[8] Identical
...
<18382 more elements>
-------
seqinfo: 24 sequences from an unspecified genome; no seqlengths
RStudioから使えるR Markdownで日本語のPDFを作成する
RStudioではRの実行結果を埋め込んでドキュメントやレポートを作成するのにLaTeXベースのものとMarkdown(の亜種のR Markdown)ベースのものが選べるのですが、R Markdownから日本語を含んだレポートをPDF化するのに手間取ったのでその方法を記述します。 私の環境はMac OS X Mavericksですが、他の環境でも共通する点はあると思います。
準備
まずMarkdownをLaTeXにするPandocとLaTeXの処理系(XeLaTeX)が必要です。
恐らくPandocに関してはRStudioに同封されているので問題無いと思います。
LaTeXの処理系に関してはMacTeXを利用するのが最も手早いです。しかし、2GB以上もある巨大なファイルをダウンロードし、インストールする羽目になるので、コアだけを集めたBasicTeXでも十分です。
BasicTeXをインストールしたら、いくつか必要なパッケージをインストールします1:
sudo tlmgr update --self --all sudo tlmgr install framed sudo tlmgr install titling sudo tlmgr install collection-langjapanese
設定
続いてRStudioを起動し、必要な設定を行います。
“RStudio” ➠ “Preferences…” ➠ “Sweave”と選択し、取り敢えずデフォルトをの設定を以下のようにします。
- Weave Rnw files using: knitr
- Typeset LaTeX into PDF using: XeLaTeX
- Preview PDF after compile using: System Viewer
最後の設定はRStudioのPDFビューアーが気に入らなかっただけで、私の好みです(PDF Reader Xを使っています)。
また、この設定はデフォルトのもので、プロジェクトでは別個に設定する必要があります。

R Markdownファイルの作成
“File” ➠ “New File” ➠ “R Markdown…” と選択し、適当にタイトルを設定してR Mawkdownのひな形作成します。ここでは、タイトルは「日本語PDF作成」としました。

しかし、これだけではプロジェクトの設定が反映され、先ほどのデフォルト設定が無視されてしまう場合があります。 そこで、ファイルの先頭を以下のように変更します。
変更前:
--- title: “日本語PDF作成” output: pdf_document ---
変更後:
---
title: “日本語PDF作成"
output:
pdf_document:
latex_engine: xelatex
mainfont: Hiragino Kaku Gothic Pro
---
latex_engineとしてxelatexを設定することで、UTF8などのエンコーディングに対応できるようになり、mainfontを設定することで、出来上がったPDFファイルの日本語フォントが表示されなくなる問題を修正しています。
ここでは、Hiragino Kaku Gothic Proを使いましたが、MacのFont Bookから、日本語に対応した好きなフォントを選ぶこともできます。
最後に日本語を含むR Markdownを書き、”Knit PDF”をクリックするとPDFが表示されます。
